Messing around with fine-tuning LLMs
Fine-tuning an LLM is how you take a base model and turn it into something that can actually do something useful. Base models are LLMs that have been trained to learn to predict the next word on vast amounts of text, and they're really interesting to play with, but you can't really have a conversation with one. When you ask them to complete some text, they don't know whether you want to complete it as part of a novel, a technical article, or an unhinged tweetstorm. (The obvious joke about which type of people the same applies to is left as an exercise for the reader.)
Chat-like AIs like ChatGPT become possible when a base model has been fine-tuned on lots of texts representing transcriptions (real or fake) of conversations, so that they specialise in looking at texts like this:
Human: Hello!
Bot: Hello, I'm a helpful bot. What can I do for you today?
Human: What's the capital city of France?
Bot:
...and can work out that the next word should be something like "The", and then "capital", and so on to complete the sentence: "of France is Paris. Is there anything else I can help you with?"
Getting a solid intuition for how this all works felt like an interesting thing to do, and here are my lab notes on the first steps.
Somewhat arbitrarily, I decided that I wanted to get to a stage where I could fine-tune the Llama 3 8B base model on a dataset that taught it how to follow instructions. Obviously the result would not be half as good as Meta's own instruction-tuned model, which has been fine-tuned on huge amounts of data, by people much more knowledgeable about these things than I am, but this is a learning exercise rather than an attempt to produce a generally useful artefact at the end, so that doesn't matter.
Also relatively arbitrarily, I decided to use the openassistant-guanaco dataset by Tim Dettmers on Hugging Face. It (and variants thereof) seem to be used by a lot of different fine-tuning tutorials out there -- so presumably it works pretty well.
My final initial decision was that I was going to fine-tune the model in "full-fat" mode -- that is, no quantization (squashing the parameters from 16-bit to 8- or 4-bit to use up less RAM on the graphics card [VRAM in what follows]), and no tricks like LoRA (which allows you to train just a subset of the parameters, again saving on the resources used in the training). This was going to be a full-on gradient descent on every parameter of the model, just like the original training.
Now, with the 24GiB on my graphics card, I can only just store the 8B model that I ultimately want to train. Fine-tuning will certainly use much more; it needs to store the gradients, the fine-tuning data, and so on -- indeed, getting a feel for how much more VRAM it would need is one of the things I wanted to achieve with this project. It's public knowledge that LLMs like GPT-4 used tens of thousands of H100 cards (80GiB each) for weeks, or perhaps months, during their training, but they're generally believed to just have between a few hundred billion to a trillion or so parameters, so they should fit into couple of dozen cards. What does all of that extra hardware do, and what does using it buy you?
Still, while I couldn't train the model I had in mind on my own machine, I didn't want to leap right in and start using rented GPUs, because I figured I'd be slow and make lots of silly mistakes at the start. Better to try some smaller experiments first locally. What could I fine-tune on my own machine?
With some digging around I found this helpful chart of what the VRAM requirements are for different kinds of fine-tuning. For full tuning, you need 160GiB for 7B, 320GiB for 13B, 600GiB for 30B, and so on. The relationship looks pretty much linear; you need about 20GiB for each billion parameters. (You can also see the huge advantages in terms of resource usage for quantised models and LoRA on that chart.)
Those numbers are for a specific fine-tuning framework, but my guess (which proved right) was that if I put together something that wasn't completely broken, the same kind of ratio would work. So with 24GiB VRAM, it looked like a 1B model might work. Weirdly enough, I found it very difficult to find one -- there are a few 1.5B models on Hugging Face, but very little less than that. Eventually I hit upon Qwen/Qwen1.5-0.5B, a 0.5B model released by Alibaba. So thats what I decided to use.
At this point, it's probably best to point you straight at the notebook where I did this initial experiment. The comments in there do a better step-by-step explanation as to how the code works than I would do here, so I'll focus on what I discovered that might not be obvious from the code.
VRAM usage
- The length of each training sample you send to the LLM really matters! Although the notebook has some code to map out the length of the training and test samples, and then chooses 2048 tokens as the cutoff length for the data sent to the LLM for training, for my initial tests I just picked 512 tokens as a cutoff because that was what one of the tutorials I was using used. Bumping the length of the data I sent to the LLM up increased VRAM use linearly -- that is, twice the length was twice the VRAM usage.
- Batch sizes also matter; unsurprisingly, a batch size of two -- that is, when you're tuning, you tune on two examples at the same time -- uses twice the VRAM as when you're using a batch size of one, and the relationship is again linear as you scale up the batch size.
[Update, later: this isn't quite true -- the relationships are linear but there's
a constant term in there -- y = ax + b rather than y = ax.]
This, I think, gives a good indication as to a reason why so much in the way of resources is required for a training run of a big LLM. You naturally want the data sent to the LLM for training to be as long as possible -- ideally as long as its context window -- so that it's fully trained on long-form data. But you also want the batch size to be as large as possible, because the more training data you can train on in parallel, the faster you're going to get the job done.
Let's do a back-of-an-envelope calculation.
- With 512-token inputs, I could use a batch size of seven on a 0.5B model (pretty much filling up the VRAM).
- With 2048-token inputs, I could use a batch size of one on a 0.5B model (with some unused space).
As the first case was closer to using up the 22GiB that are available on my graphics card after Chrome, X, alacritty and so on have taken their pound of flesh, let's use that as a baseline, and then try to scale it to 400B (on the low end of guesses I've seen for GPT-4) and an 8k-token input size, assuming the numbers are linear:
- 512 tokens and 0.5B parameters -> seven inputs in 22GiB
- 512 tokens and 0.5B parameters -> 3GiB/input
- 8k tokens and 0.5B parameters -> 48GiB/input
- 8k tokens and 400B parameters -> 38,400GiB/input
Yikes. Now I'm sure that there are constant terms and all kinds of other things missing from that calculation, but I suspect it's at least correct to within a few orders of magnitude. And remember, that's just for a batch size of one! We're only training on one example text at a time. Numbers are hard to come by, but I have a vague memory of hearing that GPT-4 was trained on about 3 trillion tokens. Certainly, Llama 3 was trained on about 15 trillion, and this was presented in various news outlets as being significantly larger than was believed to be used for earlier models, so let's go with that.
3 trillion tokens divided by 8k is 375,000,000. I was getting about 45 minutes per epoch, so if my graphics card had a RAM upgrade to 39TiB, it would be able to do that in 16,875,000,000 minutes, which is 11,718,750 days, or 32,106 years. [Update, later: it's even worse! Time per epoch, not just VRAM usage, is proportional to the length in tokens of each sample, so we have a futher 4x term in here. I've not allowed for that in the analysis below.]
Best cancel that big GDDR6X order I put on AliExpress the other day, then.
"But," you might say, "you're ignoring the fact that by having lots of cards working on this, they don't just get more RAM. 38,400 GiB VRAM, with each H100 having 80GiB, means that they would have 480 cards, and they would all contribute processor power as well as memory." Well, yes -- but remember, we're processing one 8k training text at a time with this. Our batch size is one. There's going to be inter-card latencies between cards within the same machine, and network latencies between the machines, so if the machines are all working on one closely-connected LLM on one training sample, the advantage of having a bunch of GPUs doing the processing is going to be at least somewhat limited.
That said, I'm reasoning under very little knowledge here -- and that is why this is such an interesting project, because in order to fine-tune the 8B model I'm going to need a machine with two or more GPUs, and I'll hopefully be able to start getting a better intuition for that then.
But sticking with this really basic calculation for now, let's see what happens if we have lots of machines. Let's assume 10,000 cards. 480 cards per training sample means that we can run with a batch size of about 21. So instead of taking 32,106 years it would take a mere 1,528.
But wait, it gets worse! All of the numbers above are for one epoch. How many epochs do models get trained for? That feels like it would be worth experimenting with; perhaps my next project, once I've got more of a feel for this side of things, will need to be to find out how many runs through the training set you need to get a good next-token predictor.
But let's stop here with the speculation; I'll just finish it by linking to
this reddit post,
where the breathless poster (it is on /r/singularity, after all) tells us that Jensen Huang of Nvidia has implied
that GPT-4 has 1.8 trillion parameters and was trained on the equivalent of
8,000 H100s over 10 trillion tokens and took about three months. That's
about 6,000 times less than my calculations above (and with more tokens and
more parameters). Best guess: your predicted interjection above was correct,
and the extra processing power counts for quite a lot!
And also, I suspect that OpenAI are using more optimised training code than my cobbled-together Transformers notebook.
Let's move on to some of the other things I found interesting in this fine-tune.
Overfitting
In the notebook, you'll see that I only ran two epochs of training. What I found was that pretty consistently, the training loss dropped nicely with each epoch, but the test loss started growing after the second epoch. Here's an example:
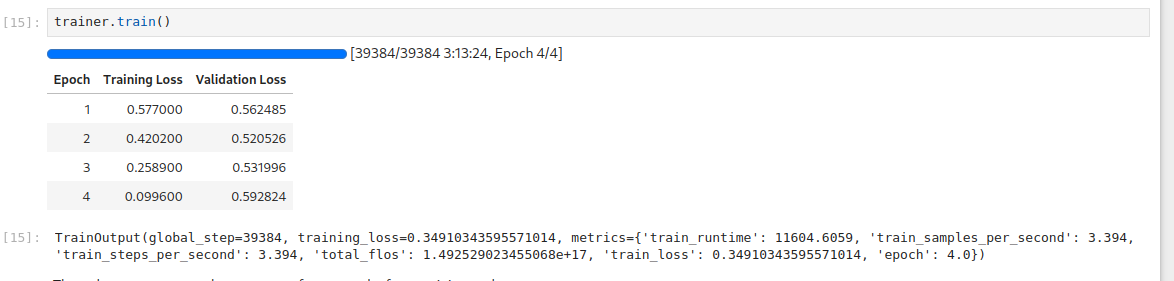
In a longer training run, things got even worse -- training loss was dropping to 0.01 or so, while test loss went up above 4. Thinking about it, that's not all that surprising. We have a 0.5B parameter model and we're training it on about 4k samples of 2k tokens each. That's 8MiB of data to memorise across 1GiB of weights. So no surprise that it can just learn the training set and get worse at the test set.
There's probably a rule of thumb to be learned here regarding the number of epochs, the size of the model, and the size of your fine-tuning set (or perhaps even your training set for a base model). More experiments needed!
One second experiment I ran was to see if the data format might be conducive to overfitting. My logic was something like this:
- The format of the dataset I'm using looks a bit like markdown.
- The base LLM I'm using has probably seen a lot of markdown and might be good at fitting stuff to it.
- If I use a very non-markdown format for the training data, it might find it more confusing and then learn it less easily, potentially with a better result in learning how to answer questions.
This was a very loosely-held theory, but I thought it would be interesting to check, so I changed the format of the dataset from the original to one based on the instruction format that was used for the instruction-tuned versions of the Llama-2 series; here's the notebook. As you can see, it had absolutely no impact at all; overfitting happened after the second epoch of training. It was a good exercise in massaging training data, though.
Checkpoint size
As part of investigating the whole overfitting thing, I decided to do an overnight run with 64 epochs (I was using a 512-token sample size at the time, so it was taking about 15 minutes per epoch). When I checked the following morning, it had crashed due to running out of disk space. It had used almost 600GiB overnight! It looks like it was checkpointing a couple of times per iteration, and each one took up just less than 6GiB.
Note to self: get bigger disks.
Conclusion
So, what have I learned from all of this?
Training is much harder (for the computer, at least) than inference. This is no surprise, I was aware of that before I'd even started messing around with AI stuff. But this gave me the beginnings of an intuition into how much harder it is.
But training, at least at this small scale, isn't actually that much harder for the programmer than inference. I'm sure a metric shit-ton of complexity is being hidden from me by the libraries I'm using, and I suspect that it won't be that many more experiments and blog posts before I start wanting to write stuff at a lower level to find out exactly what these tools I'm using are doing under the hood.
But I think that the most useful thing I've learned so far is that I can do proper experiments with small models on my consumer-grade hardware. I have what amounts to a mid- to high-end gaming machine, with an RTX3090 and an i7, and 64GiB RAM. With that I can train and play with 0.5B parameter models, albeit somewhat slowly. But in order to do anything larger-scale, I'd need much more serious hardware -- importantly to me, it would have to be significantly more expensive than I could sensibly pay for. Upgrading to an Epyc or whatever so that I have enough PCI lanes to add on a few extra 3090s, and then working out how to cool something that's running at a couple of kW of power... not worth it.
So the next step is to see what I can do on a machine that I can affordably rent for the training runs. Can I get a machine with 160GiB VRAM affordably? And can I run the same fine-tune code on it and get useful results? And can I get to a place where I can run local experiments on small models and then have the knowledge I get from them port over to larger ones running remotely?
Stay tuned...