Writing an LLM from scratch, part 7 -- wrapping up non-trainable self-attention
This is the seventh post in my series of notes on Sebastian Raschka's book "Build a Large Language Model (from Scratch)". Each time I read part of it, I'm posting about what I found interesting or needed to think hard about, as a way to help get things straight in my own head -- and perhaps to help anyone else that is working through it too.
This post is a quick one, covering just section 3.3.2, "Computing attention weights for all input tokens". I'm covering it in a post on its own because it gets things in place for what feels like the hardest part to grasp at an intuitive level -- how we actually design a system that can learn how to generate attention weights, which is the subject of the next section, 3.4. My linear algebra is super-rusty, and while going through this one, I needed to relearn some stuff that I think I must have forgotten sometime late last century...
Michael Foord: RIP
Michael Foord, a colleague and friend, passed away this weekend. His passing leaves a huge gap in the Python community.
I first heard from him in early 2006. Some friends and I had just started a new company and there were two of us on the team, both experienced software developers. We'd just hired our third dev, another career coder, but as an XP shop that paired on all production code, we needed a fourth. We posted on the Python.org jobs list to see who we could find, and we got a bunch of applications, among them one from the cryptically-named Fuzzyman, a sales manager at a building supplies merchant who was planning a career change to programming.
He'd been coding as a hobby (I think because a game he enjoyed supported Python scripting), and while he was a bit of an unusual candidate, he wowed us when he came in. But even then, we almost didn't hire him -- there was another person who was also really good, and a bit more conventional, so initially we made an offer to them. To our great fortune, the other person turned the offer down and we asked Michael to join the team. I wrote to my co-founders "it was an extremely close thing and - now that the dust is settling - I think [Michael] may have been the better choice anyway."
That was certainly right! Michael's outgoing and friendly nature changed the company's culture from an inward-facing group of geeks to active members of the UK Python community. He got us sponsoring and attending PyCon UK, and then PyCon US, and (not entirely to our surprise) when we arrived at the conferences, we found that he already appeared to be best friends with everyone. It's entirely possible that he'd never actually met anyone there before -- with Michael, you could never be sure.
Michael's warm-hearted outgoing personality, and his rapidly developing technical skills, made him become an ever-more visible character in the Python community, and he became almost the company's front man. I'm sure a bunch of people only joined our team later because they'd met him first.
I remember him asking one day whether we would consider open-sourcing the rather rudimentary mocking framework we'd built for our internal unit-testing. I was uncertain, and suggested that perhaps he would be better off using it for inspiration while writing his own, better one. He certainly managed to do that.
Sadly things didn't work out with that business, and Michael decided to go his own way in 2009, but we stayed in touch. One of the great things about him was that when you met him after multiple months, or even years, you could pick up again just where you left off. At conferences, if you found yourself without anyone you knew, you could just follow the sound of his booming laugh to know where the fun crowd were hanging out. We kept in touch over Facebook, and I always looked forward to the latest loony posts from Michael Foord, or Michael Fnord as he posted as during his fairly-frequent bans...
This weekend's news came as a terrible shock, and I really feel that we've lost a little bit of the soul of the Python community. Rest in peace, Michael -- the world is a sadder and less wonderfully crazy place without you.
[Update: I was reading through some old emails and spotted that he was telling me I should start blogging in late 2006. So this very blog's existence is probably a direct result of Michael's advice. Please don't hold it against his memory ;-)]
[Update: there's a wonderful thread on discuss.python.org
where people are posting their memories. I highly recommend reading it, and
posting to it if you knew Michael.]
An AI chatroom (a few steps further)
Still playing hooky from "Build a Large Language Model (from Scratch)" -- I was on our support rota today and felt a little drained afterwards, so decided to finish off my AI chatroom. The the codebase is now in a state where I'm reasonably happy with it -- it's not production-grade code by any stretch of the imagination, but the structure is acceptable, and it has the basic functionality I wanted:
- A configurable set of AIs
- Compatibility with the OpenAI API (for OpenAI itself, Grok and DeepSeek) and with Anthropic's (for Claude).
- Persistent history so that you can start a chat and have it survive a restart of the bot.
- Pretty reasonable behaviour of the AIs, with them building on what each other say.
An AI chatroom (beginnings)
So, I know that I decided I would follow a "no side quests" rule while reading Sebastian Raschka's book "Build a Large Language Model (from Scratch)", but rules are made to be broken.
I've started building a simple Telegram bot that can be used to chat with multiple AI models at the same time, the goal being to allow them to have limited interaction with each other. I'm not sure if it's going to work well, and it's very much a work-in-progress -- but here's the repo.
More info below the fold.
Writing an LLM from scratch, part 3
I'm reading Sebastian Raschka's book "Build a Large Language Model (from Scratch)", and posting about what I found interesting every day that I read some of it.
Here's a link to the previous post in this series.
Today I was working through the second half of Chapter 2, "Working with text data", which I'd started just before Christmas. Only two days off, so it was reasonably fresh in my mind :-)
Writing an LLM from scratch, part 2
I'm reading Sebastian Raschka's book "Build a Large Language Model (from Scratch)", and planning to post every day (or at least, every day I read some of it -- Christmas day I suspect I'll not be posting) with notes on what I found interesting.
Here's a link to the previous post in this series.
I had been planning to do a chapter a day, but that is looking optimistic for such a dense book! So today, I've read the first half or so of Chapter 2, "Working with text data". This gives an overview of the pre-processing that happens to text before it hits the LLM, goes on to describe a simple tokenization system (complete with source code), and then briefly covers the byte pair encoding method that we'll actually be using for the LLM.
Messing around with fine-tuning LLMs, part 10 -- finally training the model!
For many months now, I've intermittently been working on building code to fine-tune an 8B model -- specifically, the Llama 3 8B base model -- on the openassistant-guanaco dataset, without using tricks like quantization or LoRA. I've been taking my time and letting myself be diverted by anything that looked interesting along the way, because the goal was to learn as much as possible about how this stuff works rather than to achieve a simple goal.
But all good things must come to an end. In this post I'll document the final steps of fine-tuning the model and getting it posted on Hugging Face.
Just to summarise what's happened so far, I have:
- Fine-tuned a 0.5B model on my own machine.
- Done the same, but in the cloud using Lambda Labs.
- Run some multi-GPU training, but using the GPUs to run larger batches for the 0.5B model -- which in turn means training faster -- rather than to train a larger model.
- Successfully fine-tuned the 8B model across multiple GPUs using ZeRO and DeepSpeed, but with the optimizer offloaded to CPU.
- Done some initial experiments into memory usage for a 0.5B model locally to get some ideas as to why I had to offload the optimizer.
- Measured memory usage more systematically for the 0.5B model, also locally, to find out how it behaves with different sequence lengths.
- Made similar measurements at different sequence lengths for the 8B model.
- Measured the effect of batch sizes on memory usage, with a sidetrack into looking at Liger Kernel, a new and easy-to use replacement of the default CUDA kernels used for training that promises (and delivers) better memory usage and performance.
- Investigated how gradient checkpointing works, in the hope that it might allow me to trade off GPU processing for memory usage and get a larger batch size (meaning that each training iteration was slower, but the overall train took less time). Sadly, those hopes were dashed.
There are still a bunch of open questions left from those earlier posts, and I'm planning to do a summary post listing what those are (and, indeed what I've learned). But I figured it really was time to wrap up the final step. Check it out:
$ python chat_with_model.py gpjt/Meta-Llama-3-8B-openassistant-guanaco-llama2-format
Special tokens have been added in the vocabulary, make sure the associated word embeddings are fine-tuned or trained.
Loading checkpoint shards: 100%|============================================================================================================| 4/4 [00:03<00:00, 1.31it/s]
You: Please tell me about Leonardo da Vinci.
Bot: Sure, Leonardo da Vinci was an Italian polymath and artist who lived in the
late 15th and early 16th centuries. He is considered one of the greatest minds of
the Renaissance era, and is remembered as one of the most influential artists of
all time. Leonardo was a master of many fields, including painting, sculpting,
architecture, engineering, and science. He is best known for his paintings, such
as the Mona Lisa and The Last Supper, and for his inventions, such as the flying
machine and the helicopter. Leonardo was also a skilled mathematician, and made
important contributions to fields such as cryptography and astronomy. He died at
the age of 67, without ever fully completing any of his many projects.
251 tokens in 6.11s: 41.10 tokens/s
You: Interesting! Could you expand on what the Mona Lisa is?
Bot: The Mona Lisa is a painting by Leonardo da Vinci that depicts a portrait
of a woman from the Renaissance era. It is one of the most famous paintings in
the world, and is considered one of the most recognizable pieces of art ever
created. The painting has been the subject of numerous studies and
interpretations, and is often used as an example of the aesthetic and
intellectual values of the Renaissance period.
79 tokens in 2.01s: 39.40 tokens/s
You: Where is it? I would really like to see it.
Bot: The Mona Lisa is located in the Louvre Museum in Paris, France. It is one
of the most visited museums in the world, and is a must-see destination for
anyone interested in art and culture. The Louvre Museum is open to the public,
and admission is free on the first Sunday of every month. Tickets can also be
purchased online or at the museum entrance. There are also many other museums and
attractions in Paris, such as the Eiffel Tower and the Notre Dame Cathedral, that
are worth visiting while you are in the city.
112 tokens in 2.81s: 39.90 tokens/s
You: Sounds cool! What food should I try while I'm there?
Bot: While you are in Paris, you should definitely try some of the delicious
French food! Some must-see dining spots are:
- Le Relais de l'Entrecôte: a classic French bistro where you can enjoy a delicious steak with a side of French fries.
- L'Ami Jean: a hip and trendy restaurant that serves up delicious French food with a modern twist.
- Le Bistrot Paul Bert: a charming bistro that serves up classic French dishes with a focus on fresh, local ingredients.
- L'Assiette: a dining room that serves up delicious French food in a beautiful dining room.
- L'Ami Louis: a classic French restaurant that has been serving up delicious food for over 100 years.
I hope you enjoy your trip to Paris, and that you have a delicious dining experience
while you are there!
174 tokens in 4.38s: 39.70 tokens/s
And so on. The script is here,
and you can run it against any model that accepts the
Llama 2 prompt format
-- see the command I used to start it above.
There's an optional --debug flag so that you can see everything sent to and
from the model.
So, about this one: it can't count the "r"s in strawberry, but it's a working assistant bot! Success :-)
Let's dig in to how it was fine-tuned.
Messing around with fine-tuning LLMs, part 9 -- gradient checkpointing
This is the 9th installment in my ongoing investigations into fine-tuning LLM models. My goal is to fine-tune an 8B model -- specifically, the Llama 3 8B base model -- on the openassistant-guanaco dataset, without using tricks like quantization or LoRA. I'm doing this as a way to try to understand how to do full-on multi-GPU training of a model that cannot be trained on just one GPU -- so I'm taking it super-slowly and stopping and measuring everything along the way, which means that I'm learning a ton of new stuff pretty effectively.
So far, I've:
- Fine-tuned a 0.5B model on my own machine.
- Done the same, but in the cloud using Lambda Labs.
- Run some multi-GPU training, but using the GPUs to run larger batches for the 0.5B model -- which in turn means training faster -- rather than to train a larger model.
- Successfully fine-tuned the 8B model across multiple GPUs using ZeRO and DeepSpeed, but with the optimizer offloaded to CPU.
- Done some initial experiments into memory usage for a 0.5B model locally to get some ideas as to why I had to offload the optimizer.
- Measured memory usage more systematically for the 0.5B model, also locally, to find out how it behaves with different sequence lengths.
- Made similar measurements at different sequence lengths for the 8B model.
- Measured the effect of batch sizes on memory usage, with a sidetrack into looking at Liger Kernel, a new and easy-to use replacement of the default CUDA kernels used for training that promises (and delivers) better memory usage and performance.
I'll look into Liger in more depth in a future post, because it looks incredibly useful, but first I wanted to investigate something that I learned about as a result of my original post about it. I posted my results on X, and Byron Hsu (who's building Liger at LinkedIn) thought it was weird that I was only able to squeeze a batch size of two (without Liger) or three (with it) into an 8x A100 80 GiB machine. In the Liger GitHub repo, they have an example of the kind of memory improvements the new kernels can provide; it shows without-Liger memory usages of (roughly) 55 GiB at a batch size of 32, 67 GiB at 48, and an OOM with 64. Now, they're using a sequence length of 512 rather than the 2048 I've been using, and that would have an effect, but not enough to allow batches that were sixteen times larger -- expecially because their benchmarks were being run on a machine with four A100 80 GiB cards, not eight.
Byron and I had a quick chat just to see if there was anything obviously dumb going on in my configuration, and one thing that stood out to him was that I wasn't using gradient checkpointing (which the Liger example is doing). That was something I'd very briefly looked into back in my earliest experiments into tuning the 8B model; I was following a Hugging Face guide to what to do if you hit memory problems. In their guide to DeepSpeed, they write:
A general process you can use is (start with batch size of 1):
- enable gradient checkpointing
- try ZeRO-2
- try ZeRO-2 and offload the optimizer
I had tried running my tune with both the gradient checkpointing enabled and Zero-2, but it blew up at iteration 24 (my first indication that there was something that kicked in at that point that increased memory usage), so I'd moved straight on to the optimizer offload.
At that point I was using instances with 8x A100 40 GiB. Since then, I'd switched to using 80 GiB per GPU machines, and done various tests comparing performance:
- With no gradient checkpointing, ZeRO 3 and no optimizer offload, versus
- With gradient checkpointing, ZeRO 2, and the optimizer offloaded.
But what would happen if I just tried Zero 3 with no optimizer offload, with and without gradient checkpointing? That really sounded worth a look.
So, while I finished off my last post by saying
I think I'm finally in a place where I can do what should be the last experiment in this series: a full fine-tune of the Llama 3 8B base model -- on the openassistant-guanaco dataset, without using tricks like quantization or LoRA.
...it now looks like there's something well worth investigating first: gradient checkpointing.
Messing around with fine-tuning LLMs, part 8 -- detailed memory usage across batch sizes
This is the 8th installment in a mammoth project that I've been plugging away at since April. My goal is to fine-tune an 8B model -- specifically, the Llama 3 8B base model -- on the openassistant-guanaco dataset, without using tricks like quantization or LoRA. I'm doing this as a way to try to understand how to do full-on multi-GPU training of a model that cannot be trained on just one GPU -- so I'm taking it super-slowly and stopping and measuring everything along the way.
So far, I've:
- Fine-tuned a 0.5B model on my own machine.
- Done the same, but in the cloud using Lambda Labs.
- Run some multi-GPU training, but using the GPUs to run larger batches for the 0.5B model -- which in turn means training faster -- rather than to train a larger model.
- Successfully fine-tuned the 8B model across multiple GPUs using ZeRO and DeepSpeed, but with the optimizer offloaded to CPU.
- Done some initial experiments into memory usage for a 0.5B model locally to get some ideas as to why I had to offload the optimizer.
- Measured memory usage more systematically for the 0.5B model, also locally, to find out how it behaves with different sequence lengths.
- Made similar measurements for the 8B model.
I'd reached the conclusion that the only safe way to find out how much memory a fine-tune of either of the models I was working with would use was just to try it. The memory usage was important for three reasons -- firstly, whether the model could be trained at all on hardware I had easy access to, secondly, if it could be trained, whether I'd need to offload the optimizer (which had a serious performance impact), and thirdly what the batch size would be -- larger batches mean much better training speed.
This time around I wanted to work out how much of an impact the batch size would have -- how does it affect memory usage and speed? I had the feeling that it was essentially linear, but I wanted to see if that really was the case.
Here's what I found.
Messing around with fine-tuning LLMs, part 7 -- detailed memory usage across sequence lengths for an 8B model
My goal is to fine-tune an 8B model -- specifically, the Llama 3 8B base model -- on the openassistant-guanaco dataset, without using tricks like quantization or LoRA. I'm doing this as a way to try to understand how to do full-on multi-GPU training of a model that cannot be trained on just one GPU.
I've been building up to this goal gradually; so far, I've:
- Fine-tuned a 0.5B model on my own machine.
- Done the same, but in the cloud using Lambda Labs.
- Run some multi-GPU training, but using the GPUs to run larger batches for the 0.5B model -- which in turn means training faster -- rather than to train a larger model.
- Successfully fine-tuned the 8B model across multiple GPUs using ZeRO and DeepSpeed, but with the optimizer offloaded to CPU.
- Done some initial experiments into memory usage for a 0.5B model locally to get some ideas as to why I had to offload the optimizer.
- Measured memory usage more systematically for the 0.5B model, also locally, to find out how it behaves with different sequence lengths.
My tentative conclusion from the last post was that perhaps the function I was using
to estimate per-GPU memory usage, estimate_zero3_model_states_mem_needs_all_live,
might be accurate with a sequence length of 1. Right back at
the start of these experiments, I'd realised that the
sequence length is an important factor when
working out RAM requirements, and the function didn't take it as a parameter --
which, TBH, should have made it clear to me from the start that it didn't have
enough information to estimate numbers for fine-tuning an LLM.
In my last experiments, I measured the memory usage when training the 0.5B model at different sequence lengths and found that it was completely flat up to iteration 918, then rose linearly. Graphing those real numbers against a calculated linear approximation for that second segment gave this ("env var" in the legend refers to the environment variable to switch on expandable segments, about which much more later -- the blue line is the measured allocated memory usage):
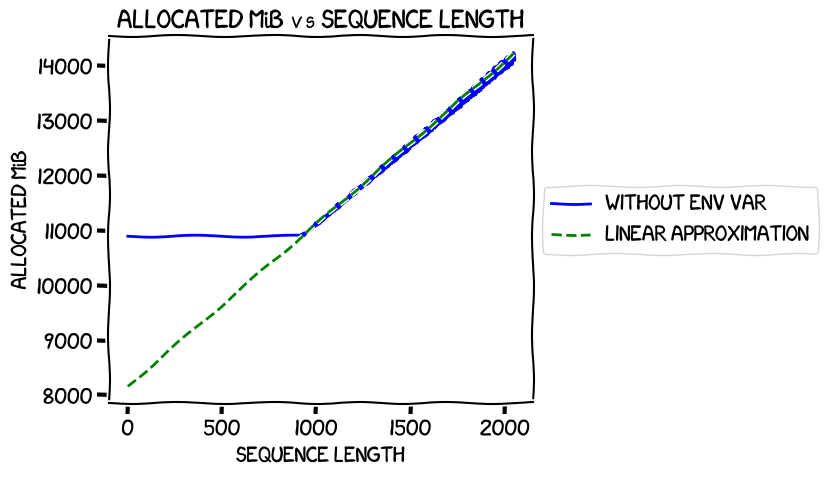
It intersected the Y axis at around 8 GiB -- pretty much the number estimated
by estimate_zero3_model_states_mem_needs_all_live.
So, this time around I wanted to train the 8B model, and see if I got the same kind of results. There were two variables I wanted to tweak:
- Expandable segments. Setting the environment variable
PYTORCH_CUDA_ALLOC_CONFtoexpandable_segments:Truehad reduced the memory usage of the training quite significantly. After some initial confusion about what it did, I had come to the conclusion that it was a new experimental way of managing CUDA memory, and from the numbers I was seeing it was a good thing: lower memory usage and slightly better performance. I wanted to see if that held for multi-GPU training. - Offloading the optimizer. I had needed to do that for my original successful fine-tune of the 8B model because not doing it meant that I needed more than the 40 GiB I had available on each of the 8 GPUs on the machine I was using. What was the impact of using it on memory and performance?
So I needed to run four tests, covering the with/without expandable segments and with/without optimizer offload. For each test, I'd run the same code as I did in the last post, measuring the numbers at different sequence lengths.
Here's what I found.