Messing around with fine-tuning LLMs, part 4 -- training cross-GPU.
My goal is to fine-tune an 8B model -- specifically, the Llama 3 8B base model -- on the openassistant-guanaco dataset. I'm doing this as a way to try to understand how to do full-on multi-GPU training of a model that literally cannot be trained on just one GPU. I've been building up to this goal gradually; so far, I've:
- Fine-tuned a 0.5B model on my own machine.
- Done the same, but in the cloud using Lambda Labs.
- Run some multi-GPU training, but using the GPUs to run larger batches -- which in turn means training faster -- rather than to train a larger model.
In that last step, I'd found a very useful page in the Hugging Face documentation. It split multi-GPU situations into three categories:
- Your model fits onto on a GPU.
- Your model doesn't fit onto a GPU (but the layers taken individually do).
- The largest layer in your model is so big that it doesn't fit onto a GPU.
I'd interpreted that first point as "you can load the model onto just one GPU" -- that is, you can run inference on it because all of the parameters fit there (with some overhead for the data, activations, etc). However, my experiences showed that it meant "you can train the model on one GPU", which takes up significantly more VRAM than inference does. The suggested approaches they had for that category were all about having the model loaded and training on each GPU, which is good for speeding up training by training on multiple batches simultaneously, but doesn't help if you want multiple GPUs simply because you can't train the model on one GPU alone.
So my goal this time was to change my training strategy to use a technique that allowed the training of the entire model to be split across GPUs. Here's what I did.
Getting set up, and a first experiment
The first step was to write a new script,
first-8B-fine-tune.py.
I tried to run it locally (pretty much as just a basic syntax/typo check) and, as
expected, it blew up with a CUDA out-of-memory error.
Now, I'd got the impression from some very-much-not in-depth research that an 8B model should be trainable with 160GiB or so VRAM. But perhaps that was wrong, and I could do it with less? I decided to give it a whirl with an 80GiB card. The only machine that was available on Lambda Labs at the time with cards with that much VRAM was an 8x H100 machine, with each card having 80GiB. This cost a relatively eye-watering $27.92/hour, but I only would be using it for a few minutes. It took 5 minutes to boot (a long time by the standards of the machines I'd been using) and then:
git clone https://github.com/gpjt/fine-tune-2024-04.git
cd fine-tune-2024-04
sudo apt install -y virtualenvwrapper
source /usr/share/virtualenvwrapper/virtualenvwrapper.sh
mkvirtualenv fine-tune
pip install -r requirements.txt
(If you're following along and remember the startup stuff I did on the machines
previously, you'll see that I skipped the ipython kernel install stuff, because
I'm no longer using notebooks.)
I then set an environment variable to make sure that my code would have access
to Meta-Llama-3-8B -- it's a gated model, so you need a Hugging Face API
key in place to download and use it:
export HF_TOKEN=XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXx
...and then I could run it:
torchrun first-8B-fine-tune.py
It took 4 minutes to download the model, and then I got an error:
ValueError: Asking to pad but the tokenizer does not have a padding token. Please select a token to use as <!--CODE_BLOCK_3575--> <!--CODE_BLOCK_3576--> or add a new pad token via <!--CODE_BLOCK_3577-->.
The message is pretty self-explanatory, so I added this to the code just after I created the tokenizer (you'll see this in the code in the version linked above):
tokenizer.pad_token = tokenizer.eos_token
I ran it again -- and got the expected OOM error in trainer.train(). I decided
to try it without the torchrun overhead:
python first-8B-fine-tune.py
...and exactly the same error. So I shut down the machine. $4.84 to run that experiment; now I know how CERN feel ;-)
It was a bit of a pity that there wasn't a machine where I could do pure single-GPU training on the model, because the VRAM it needed would be an interesting comparison point for how how much you need when splitting the work over multiple GPUs. But it wasn't surprising that it didn't fit into 80GiB, considering that the 0.5B model needed 15.83GIB. That's a ratio of about 1:30, so an 8B model would need 240GiB, if it's linear.
So it was time to choose a multi-GPU strategy that doesn't just speed things up for smaller models, but instead makes it possible to train larger models.
Choosing a strategy
Going back to those categories from that HF help page, we were hopefully in the second one: "Your model doesn't fit onto a GPU (but the layers taken individually do)." I say hopefully, because there's a step change in difficulty between successive categories in that list. So let's see what they say about this case:
Case 2: Your model doesn't fit onto a single GPU:
If your model is too large for a single GPU, you have several alternatives to consider:
- PipelineParallel (PP)
- ZeRO
- TensorParallel (TP)
With very fast inter-node connectivity (e.g., NVLINK or NVSwitch) all three strategies (PP, ZeRO, TP) should result in similar performance. However, without these, PP will be faster than TP or ZeRO. The degree of TP may also make a difference. It's best to experiment with your specific setup to determine the most suitable strategy.
Now, before reading any of this, my initial guess as to how you might be able to split a model over GPUs was that you would put each layer on one GPU. You'd send the inputs to GPU0 to do the first layer, then take the activations from there and send them to GPU1 for the next layer, and so on. If you have more layers than you have GPUs, then you might be able to squeeze a couple onto each -- say, layers 1 and 2 on GPU0, 3 and 4 on GPU1, and so on.
Delightfully, there's a name for that: Naive Model Parallelism. It has pretty obvious problems:
- After one GPU has done its calculations for its layer, it needs to pass the activations onto the next GPU, so there's a lot of communication going on.
- Because models are calculated layer-by-layer, only one GPU is going to be doing any calculations at any given time.
The first of those is kind of unavoidable -- any multi-GPU solution is going to require lots of chatter between the different cards. But the second really sounds like a waste of resources.
PipelineParallel is an improved version of this naive system, which works kind of like the instruction pipeline in a CPU. Let's say you have a batch of eight inputs you want to train on, and four layers, each on its own GPU. You'd feed in input one to the GPU0; all of the other GPUs would be idle. But then you take the outputs from GPU0, pass them on to GPU1, and feed the second input in to GPU0. Repeat that two more times, and GPU0 is processing the first layer for input 4, GPU1 is processing the second layer for input 3, GPU2 is processing the third layer for input 2, and GPU3 is finishing off the fourth layer, completing the forward pass for input 1.
Then, for the backward pass, the same thing happens, but with the GPUs working on things in the reverse order.
(There's a really nice diagram of this on the HF page, BTW. I'm only putting my own explanation here as a was of making sure that it's clear enough in my mind that I can express it simply.)
That means that you only have idle time at the start and end of the each pass; the rest of the time, all of the GPUs are busy working on different inputs.
However, on looking at the docs, I found that there's no Transformers implementation that I would be able to use, and models have to be specifically coded to use it. So this one -- despite HF's comment that it's generally as good as or faster than the others -- didn't look like an option, at least for now.
While PipelineParallel (and, indeed, Naive Model Parallelism) work by slicing the model vertically, with one GPU for each layer, ZeRO works by slicing the model "horizontally" -- eg. each GPU has some of the parameters for each of the different layers in the model. This means that in order to do a pass, either forward or backward, the GPUs need to communicate even more than they do with PP -- after all, in order to work out an activation at a particular layer, it needs all of the activations from the previous layer. So while in PP, GPU1 needs all of the activations from GPU0, GPU2 needs everything from GPU1, and so on, with ZeRO, each GPU needs to send all of the activations to all of the other GPUs. To put it another way, the total amount of data transmitted scales with the number of GPUs n as O(n) for PP, and O(n^2) for ZeRO. This is seriously communication-intensive, which explains why it's not so great if you don't have very fast inter-node connectivity.
The good news was, however, that it looked like support is fully baked into Transformers. And the 8x A100 instances that I often find available on Lambda Labs have SXM4, which means that the GPUs can talk to each other with excellent bandwidth.
Moving on to Tensor Parallelism -- it looked insanely complex, and extremely clever. Another one to look into in the future, because I'd like to understand it. However, there is partial support for it in Transformers -- and I have to note that I said pretty much the same thing about delaying learning about ZeRO due to its complexity a couple of posts ago, and (a) had to learn about it anyway and (b) didn't find the basics too hard to get my head around once I put my mind to it.
However, at this point I figured that ZeRO was the way to go. It looked like the quickest and easiest way to do that is to use DeepSpeed.
Getting started with ZeRO and DeepSpeed
I decided to try it locally first with the 0.5B model to work out the bugs. First step: pip install the
deepspeed package. It crapped out with this:
op_builder.builder.MissingCUDAException: CUDA_HOME does not exist, unable to compile CUDA op(s)
As per this GitHub issue, this
sounded like it was because
I had the CUDA runtime installed but not the CUDA compiler. I checked, and I certainly
didn't have have a command nvcc available.
I suspect that the runtime is installed as part of the regular Nvidia drivers, because I don't install anything for CUDA as part of my OS setup script (or, at least I didn't -- I do now). But anyway, clearly installing CUDA wouldn't be difficult. And, for a nice change, I'm not foreshadowing with that blasé statement.
I'm on Arch, it had been a while since I updated my machine, and I didn't want incompatible packages, so a full upgrade was the best plan:
sudo pacman -Syu
sudo pacman -S cuda
sudo reboot
Once back in, my virtualenv was broken (there must have been a Python point release
upgrade), so I deleted it, created it again with the requirements.txt, and kicked
off python third-0.5b-fine-tune-as-script.py as a test just to make sure I'd not
broken my existing stuff. It worked fine, so once again, I ran:
pip install deepspeed
...and this time, it seemed to work fine.
Now, from the help page it looked like I would need to add just one line to my training arguments in the Python script:
deepspeed="ds_config.json"
I did that in a file called third-0.5b-fine-tune-as-script-with-deepspeed.py
This would point to a file that contained the configuration for DeepSpeed. A minimal example for that from the docs appeared to be this:
{
"zero_optimization": {
"stage": 1
}
}
ChatGPT also suggested that I strip out the device_map="cuda" from the call to
AutoModelForCausalLM.from_pretrained, because DeepSpeed would handle moving things
to CUDA as appropriate, which made sense, so I did that. (Again, no foreshadowing
here -- this really was a good idea, and made me start thinking about whether having
it in there might have been the cause of all of those extra processes building up on
GPU0 when I did
the multi-GPU training in the last blog post.)
With those changes made, I tried launching it:
deepspeed --num_gpus=1 third-0.5b-fine-tune-as-script-with-deepspeed.py
I got
ModuleNotFoundError: No module named 'distutils'
...which was weird, because that would normally point to a broken virtualenv, and I had literally just created this one! Still, a quick
pip install setuptools
...fixed that. Ran it again, and:
Traceback (most recent call last):
File "/home/giles/Dev/fine-tune-2024-04/third-0.5b-fine-tune-as-script-with-deepspeed.py", line 43, in <module>
trainer.train()
File "/home/giles/.virtualenvs/fine-tune-2024-04/lib/python3.12/site-packages/transformers/trainer.py", line 1859, in train
return inner_training_loop(
^^^^^^^^^^^^^^^^^^^^
File "/home/giles/.virtualenvs/fine-tune-2024-04/lib/python3.12/site-packages/transformers/trainer.py", line 1888, in _inner_training_loop
train_dataloader = self.get_train_dataloader()
^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/home/giles/.virtualenvs/fine-tune-2024-04/lib/python3.12/site-packages/transformers/trainer.py", line 879, in get_train_dataloader
return self.accelerator.prepare(DataLoader(train_dataset, **dataloader_params))
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/home/giles/.virtualenvs/fine-tune-2024-04/lib/python3.12/site-packages/accelerate/accelerator.py", line 1266, in prepare
result = self._prepare_deepspeed(*args)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/home/giles/.virtualenvs/fine-tune-2024-04/lib/python3.12/site-packages/accelerate/accelerator.py", line 1514, in _prepare_deepspeed
"train_batch_size": batch_size_per_device
^^^^^^^^^^^^^^^^^^^^^
TypeError: unsupported operand type(s) for *: 'NoneType' and 'int'
The multiplication that was getting the error was (stripping out some eccentric newlines):
batch_size_per_device * deepspeed_plugin.get_value("gradient_accumulation_steps")
So that plus the error message means that batch_size_per_device is None. There are a few code paths
above that are setting that variable; the block starts:
if deepspeed_plugin.is_auto("train_micro_batch_size_per_gpu"):
...and in that if block there are a bunch of ways to infer it from various other
parameters that come from various other places. The else is simply:
batch_size_per_device = deepspeed_plugin.get_value("train_micro_batch_size_per_gpu")
The HF page on DeepSpeed says that "auto" is a valid choice for this hyperparameter,
and it looked like the other things it could infer it from in the True branch of the if were all set in my code,
so I though I would just try a minimal ds_config.json like this:
{
"train_micro_batch_size_per_gpu": "auto",
"zero_optimization": {
"stage": 2
}
}
And that worked! It started happily training with a estimated time to completion of 1h44m.
It was time to try again with the big model on a big machine :-)
Training with ZeRO on a big machine
First step: I copied first-8B-fine-tune.py to second-8B-fine-tune.py, and in
there removed the device_map="cuda" and added the deepspeed="ds_config.json".
Then I added that and ds_config.json, committed and pushed.
It was time to spin up the big machine. As usual for this time of day, the 8x A100 was available in Germany. I'm coming to think that it's the same machine every time, which I can greet like an old friend. "Guten Abend, Herr Supercomputer!"
I cloned the repo, installed the requirements, set the HF_TOKEN environment variable, and then:
deepspeed --num_gpus=8 second-8B-fine-tune.py
It spun up... downloaded the model... paused for something... took much longer than usual to load the checkpoint shards... Stuff started appearing in the GPUs... There was a slow ramp up in memory usage... and we started training! But suddenly:
File "/home/ubuntu/.virtualenvs/fine-tune/lib/python3.10/site-packages/torch/autograd/__init__.py", line 266, in backward
Variable._execution_engine.run_backward( # Calls into the C++ engine to run the backward pass
torch.cuda.OutOfMemoryError: CUDA out of memory. Tried to allocate 1002.00 MiB. GPU 7 has a total capacity of 39.39 GiB of which 824.00 MiB is free. Including non-PyTorch memory, this process has 38.58 GiB memory in use. Of the allocated memory 36.74 GiB is allocated by PyTorch, and 354.80 MiB is reserved by PyTorch but unallocated. If reserved but unallocated memory is large try setting PYTORCH_CUDA_ALLOC_CONF=expandable_segments:True to avoid fragmentation. See documentation for Memory Management (https://pytorch.org/docs/stable/notes/cuda.html#environment-variables)
So it blew up on the first backward pass. :-(
So, the HF DeepSpeed help page has a way to estimate RAM/VRAM usage for a model, so it was time to run that:
(fine-tune) ubuntu@130-61-28-84:~/fine-tune-2024-04$ python -c 'from transformers import AutoModel; \
from deepspeed.runtime.zero.stage3 import estimate_zero3_model_states_mem_needs_all_live; \
model = AutoModel.from_pretrained("meta-llama/Meta-Llama-3-8B"); \
estimate_zero3_model_states_mem_needs_all_live(model, num_gpus_per_node=8, num_nodes=1)'
[2024-05-17 23:19:31,667] [INFO] [real_accelerator.py:203:get_accelerator] Setting ds_accelerator to cuda (auto detect)
[WARNING] async_io requires the dev libaio .so object and headers but these were not found.
[WARNING] async_io: please install the libaio-dev package with apt
[WARNING] If libaio is already installed (perhaps from source), try setting the CFLAGS and LDFLAGS environment variables to where it can be found.
[WARNING] Please specify the CUTLASS repo directory as environment variable $CUTLASS_PATH
[WARNING] sparse_attn requires a torch version >= 1.5 and < 2.0 but detected 2.2
[WARNING] using untested triton version (2.2.0), only 1.0.0 is known to be compatible
Loading checkpoint shards: 100%|============================================================================================================| 4/4 [00:02<00:00, 1.61it/s]
Estimated memory needed for params, optim states and gradients for a:
HW: Setup with 1 node, 8 GPUs per node.
SW: Model with 7504M total params, 525M largest layer params.
per CPU | per GPU | Options
188.72GB | 1.96GB | offload_param=cpu , offload_optimizer=cpu , zero_init=1
335.50GB | 1.96GB | offload_param=cpu , offload_optimizer=cpu , zero_init=0
167.75GB | 3.70GB | offload_param=none, offload_optimizer=cpu , zero_init=1
335.50GB | 3.70GB | offload_param=none, offload_optimizer=cpu , zero_init=0
23.48GB | 17.68GB | offload_param=none, offload_optimizer=none, zero_init=1
335.50GB | 17.68GB | offload_param=none, offload_optimizer=none, zero_init=0
That looks OK; I have 40GiB VRAM per GPU, and 1.9TiB RAM for the main memory, so that
should fit even with the last, most aggressive case. And it was VRAM limits I
was hitting ("CUDA out of memory"), not regular RAM.
I was, however, unclear about the zero_init there vs the
zero_optimization/stage in the JSON, and indeed how those related to the
ZeRO-1, ZeRO-2 and ZeRO-3 mentioned in the help page.
But still, according the the HF page, ZeRO-3 is more memory efficient, so I thought
I'd change the stage in the JSON to use it -- assuming that stage set to 3 is
the same as ZeRO-3. This time I checked the CPU usage as well
as the GPU, using top -- bashtop kept exiting for some reason -- and saw that
all CPUs were super-busy during the slow stuff at the start. When loading checkpoint
shards, some of the Python processes were using > 2,000% of a CPU! That means that
each of the processes was running twenty threads, each of which was maxing out a core
(100% in top means "100% of one CPU core"). That in turn suggests a pretty
impressive amount of multi-threading given that the GIL -- the Python Global Interpreter Lock,
which stops threading from working well -- would be getting in the way
However, the CPU usage dropped off after a bit. But then the script crapped out again with the same out-of-memory issue as before -- and it looked like it happened before it even reached the first forward pass!
I decided to follow the steps in the help page for troubleshooting this kind of thing. They started:
- enable gradient checkpointing.
- try ZeRO-2
This was a code change; I added model.gradient_checkpointing_enable(), and then
I switched back to ZeRO-2 (or, at least, I changed stage in the JSON to 2, which I
suspected would be the same thing).
It looked like it was working! At 15 iterations in, it was at about 1.07 iterations/second. It did warn me as it spun up:
<!--CODE_BLOCK_3614--> is incompatible with gradient checkpointing. Setting <!--CODE_BLOCK_3615-->.
...which is a good suggestion, but sounded optional -- it had overridden my broken setting.
Then, at iteration 24, it blew up with an out of CUDA memory error again. So, the next step was:
- try ZeRO-2 and offload the optimizer
Maybe the optimizer kicks in (or has a step change in resource requirements) at 24 iterations in and that was what blew things up? Certainly worth trying.
Based on the help page, I needed to make two changes to the config JSON to do this:
From DeepSpeed==0.8.3 on, if you want to use offload, you'll also need to the following to the top level configuration because offload works best with DeepSpeed's CPU Adam optimizer.
"zero_force_ds_cpu_optimizer": false
...and in zero_optimization,
"offload_optimizer": {
"device": "cpu",
"pin_memory": true
}
I made those changes (which are not in the repo, but you can see where they would go), and ran it again. Now we were running three times slower; 3.25 seconds/iteration, or about 0.33 iterations/sec. Clearly the optimizer offload was expensive!
At the end of iteration 24, the GPU usage dropped off for a bit, but then picked up again, but we were still running! However, we were now down at 8 seconds/iteration. 6h30m to train. By iteration 37 we were up to 10s/iteration, and an estimated 7h to complete the train, so it looked like things were slowing down as we went along.
I wondered if bumping up the batch size might speed things up. We were using about 70% of GPU VRAM, so... let's see. I changed the batch size in the Python file to 2, and kicked it off.
Now we had (as of iteration 14) 4s/iteration, but of course we had half the number of iterations to go. That was promising -- and GPU memory consumption was not obviously any worse! However, at iteration 24 the GPU VRAM usage jumped up and was 75%. I decided to see how things were looking at around iteration 37.
By then we were at 11s/iteration, but still stable at 75% VRAM usage. 3h42 to completion, 5m in. So I decided to try a batch size of 4.
With this, at iteration 10 we were running at 5.56s/iteration and 35GiB/40GiB VRAM usage. I decided to see what happened at iteration 24, when we'd expect that jump.
At this point it suddenly dawned on me why VRAM usage spiked at the halfway point when it did its end-of-epoch run against the validation set, in all of my previous tests, both in this post and the previous ones -- the batch size for validation was explicitly set to 2x the training batch size! I decided that this definitely needed to drop.
I interrupted the training run, and tried again, this time with the validation batch size and the training batch size equal to each other, and with a batch size of 5 to see if I could squeeze one more in.
That OOMed, so I went back to 4 as the batch size (but kept the test batch size as the same size as the train one), and kicked it off again.
This time around I noted down the seconds/iteration, in some detail near the start and less frequently as time went on. And I could note down numbers all the way through to the end -- because, wonderfully, this fine-tune actually completed! It took 2h13 to run to completion, and (combined with the work prior to kicking it off and the false starts), cost me $34.54. I live in Portugal, so that would buy a pretty decent dinner, but all in all I think well-worth the cost.
Of course, it didn't actually save the model, so would need to run it again, but I think that there are a bunch of performance issues that need understanding and fixing before I can treat this as done anyway.
Pretty pictures
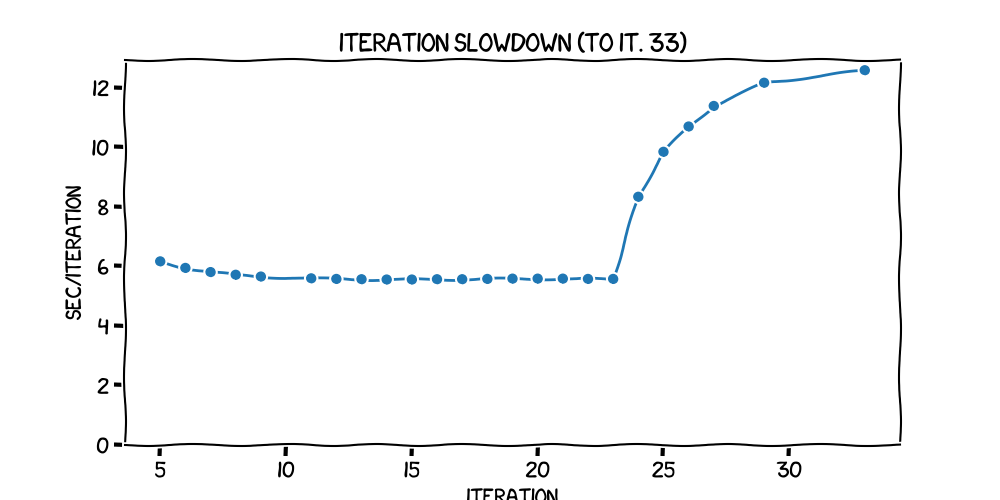
Here's what time for each iteration looked like for the first 33 iterations:
...and here's the plot over the entire run, with 616 iterations at a batch size of 4:
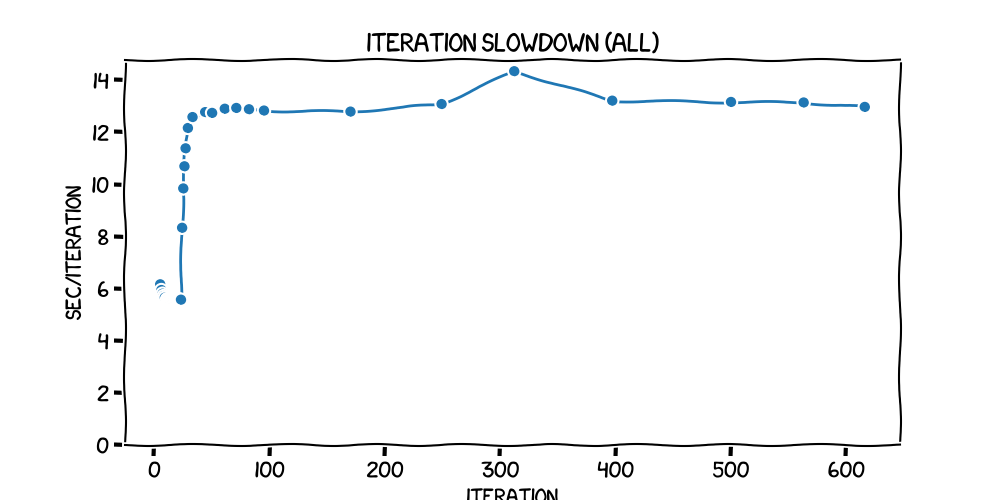
(In that second plot, it looks like pyplot or perhaps the xkcd plugin has a few issues with the points at the start being so close together.)
The raw numbers are in my charting notebook. You can see that there was a slow dropoff in time taken -- that is, an increase in speed -- from about 6.1s to 5.5s, up to iteration 24. But then, it ramped up quite quickly to a plateau at just less than 13s per iteration -- a more than doubling in time for each one. It stayed pretty much there (apart from a spike mid-train, which I think is to do with the validation run between the first and the second epoch), all the way through to the end.
One other thing from watching nvtop and top during this train; it lasted
2h13m, so I wasn't watching things closely all of the time, but I noticed that for each iteration there was a very clear double-spike pattern in GPU processor
usage; the iteration started with a spike, then there was a gap in the middle, then it ended with
another spike, then there was a gap before the next iteration started. The idle times were correlated
with times when the CPU usage spiked massively; there were 8 Python processes, and
they were each recording up to 2,000% CPU usage at these times -- another case of each one
running 20 threads at a full CPU core for each one.
This felt very much like it was the optimization that we had offloaded to the CPU by the suggested configuration. My mental model of how the whole training loop with optimization fits together is essentially non-existent, and that's another thing to backfill. But I don't remember seeing patterns like that in previous training runs.
Another odd point was the fact that the seconds per iteration had two levels: about 6 up to iteration 24, and then about 13 from then on. What might have caused that?
But still, success!
I had successfully trained an 8B model with the dataset I wanted to use :-) Of course, I hadn't saved the model, or indeed done anything with it (even a test inference) after the run, so it wasn't much use, but in a very narrow technical sense (the best kind of sense) I'd achieved my goal.
But this wasn't the right time to stop this project -- just this particular phase. There were a bunch of extra things I wanted to do before drawing a line under the experiment.
Next steps
Firstly, I wanted to train the model and store it somewhere; pushing it to Hugging Face felt like a good option. I also rather liked the modified dataset I was using back in part one, where I converted the dataset I've been using to the Llama-2 instruction format (from the original markdown-style OpenAssistant style). And pushing that dataset to HF sounded like a good idea (and might save me time in the future).
But before doing at least the first of those, it felt like it would make sense to make the train more efficient. To repeat the resource usage predictions from the DeepSpeed code I ran earlier, to train this model:
Estimated memory needed for params, optim states and gradients for a:
HW: Setup with 1 node, 8 GPUs per node.
SW: Model with 7504M total params, 525M largest layer params.
per CPU | per GPU | Options
188.72GB | 1.96GB | offload_param=cpu , offload_optimizer=cpu , zero_init=1
335.50GB | 1.96GB | offload_param=cpu , offload_optimizer=cpu , zero_init=0
167.75GB | 3.70GB | offload_param=none, offload_optimizer=cpu , zero_init=1
335.50GB | 3.70GB | offload_param=none, offload_optimizer=cpu , zero_init=0
23.48GB | 17.68GB | offload_param=none, offload_optimizer=none, zero_init=1
335.50GB | 17.68GB | offload_param=none, offload_optimizer=none, zero_init=0
Maybe it would be worth running the same test code on the 0.5B model I had been training locally, find out what it reported, and see how I could get my VRAM usages down to match -- and then bake that into the 8B script. There's clearly something I'm doing wrong, or something I don't understand about the implicit assumptions about training parameters that are baked into the code that made that estimate of resource usage. Can I get my VRAM usage down to the estimated levels?
If I could do that, a follow-up question would be: does the GPU usage double-spike pattern go away if I can get rid of the optimizer offload? That would be useful to know and might help fill in some gaps in my knowledge of how the optimizer works.
Another thing I definitely need to understand is, what do the different ZeRO levels really mean?
And how to do they fit into the different variables -- the state in the JSON file, for example?
There are also two questions that it would be interesting to answer about the previous posts (perhaps with updates there) based on things that I spotted this time around:
- What happens if I get rid of that
device_mapin theAutoModelForCausalLM.from_pretrainedin the DDP runs in my last blog post -- would that get rid of those mysterious extra processes on GPU0, and allow me to bump up my batch size and train the 0.5B model faster? - Likewise, what would happen if I drop the 2x for the test batch size for my previous experiments? Does that let me speed things up by bumping up the train batch size? I kind of blindly copied that "test batch size is double the train batch size" thing from the Fast.AI course without understanding why they suggested it. Why do they suggest it?
There's definitely more to investigate here. Stay tuned!