Messing around with fine-tuning LLMs, part 3 -- moar GPUs
Having fine-tuned a 0.5B model on my own machine, I wanted to try the same kind of tuning, but with an 8B model. I would need to do that on a cloud provider, because my own machine with its RTX 3090 would definitely not be up to the job, and I'd tried out Lambda Labs and found that it worked pretty well.
Importantly, I was going to need to train with multiple GPUs in order to do this. The Lambda Labs options open to me last time around were:
- 1x H100 (80GiB PCIe) at $2.49/hour
- 1x A10 (24GiB PCIe) at $0.75/hour
- 1x A100 (40GiB SXM4) at $1.29/hour
- 8x A100 (40GiB SXM4) at $10.32/hour
The last of those looked like it should be ample for my needs, which I'd estimated at being 160GiB VRAM (vs 320GiB on that monster machine). But before trying to use a multi-GPU setup to fine-tune a model I'd never worked with before, I figured it would be a good idea to try with the model that I've been using to date. The plan was:
- Spin up a 1x A100 and run the same fine-tune as I've been doing on it.
- If all was well, try again with the 8x A100 instance and start to learn about multi-GPU training.
Then once that was all done, I'd hopefully be in a good position to try the fine-tune for the bigger model.
Here's how it went.
Getting started
When I logged in this time, I had more options available to me in Lambda Labs; this makes me think that the types of available instances aren't related to my account (how long it's been around, spend so far, etc), but rather to what's available in their network at any given time. What I had now was (with the four that I previously had at the top):
- 1x H100 (80GiB PCIe) at $2.49/hour
- 1x A10 (24GiB PCIe) at $0.75/hour
- 1x A100 (40GiB SXM4) at $1.29/hour
- 8x A100 (40GiB SXM4) at $10.32/hour
- 8x A100 (80GiB SXM4) at $14.32/hour
- 8x Tesla V100 (16 GiB) at $4.40/hour
The two new options didn't look all that useful, so I went ahead with my original plan.
Training on a single A100 instance
This time, while spinning up the initial 1x A100 instance, I noticed that there was an option to not attach a filesystem when starting it up. This looked like a much better option for this experimental phase, so I went for that -- one fewer thing to worry about in terms of costs, as previously I'd not deleted the filesystem after shutting down my instance, and run up a $10 bill for storage in a week. Not a huge deal, but something I'd rather not have to worry about.
It spun up in a minute or two, so I logged in, cloned the repo, and then installed my requirements:
git clone https://github.com/gpjt/fine-tune-2024-04.git
cd fine-tune-2024-04
sudo apt install -y virtualenvwrapper
source /usr/share/virtualenvwrapper/virtualenvwrapper.sh
mkvirtualenv fine-tune
pip install -r requirements.txt
ipython kernel install --name gt-fine-tune-env --user
I clicked the "Cloud IDE" link in the Lambda Labs interface, and we were good to go.
I loaded up second-0.5b-fine-tune.ipynb, switched it over to use the kernel associated with my virtualenv
fine-tune, and then started thinking about running it. Now, with this
instance I had 40GiB of VRAM; my batch size was previously set to one, based on what
fit into 24GiB.
I decided to do a binary chop, starting with a batch size of 32. That was (unsurprisingly) too much, so 16 was next. That was also too much, so 8. Still too much! On to 4... that worked. So back up to 6... too much again, so we try 5... nope. So we have a batch size of 4. The whole binary chop took 3 minutes or so, so it wasn't expensive.
Interestingly, when I did the initial inference on the untuned model to see its output (cell 13 in the notebook), it generated at 54 tokens/second, which is even slower than the A10 I tried last time around, which got 63 tokens/second, which itself was slower than the 90 tokens/second I got on my local RTX 3090. But again, this comparison site had the answer: although I was expecting the A100 to be a later generation than the A10 (the number is bigger!), it turns out it was older -- released in 2020 rather than 2021, and with a lower clock speed.
But it more than made up for that with the larger batch size. I let the training run finish; in the last post, on a single A10 with 24GiB VRAM, I was able to train with a batch size of one, and got the whole thing done in 2h21m. But this time around, on a single A100, which is somewhat slower (say, 15% slower based on the tokens per second), but has 40GiB RAM, I could train with a batch size of 4, and got it done in 39m12s. That was about 3.6x faster; that's in line with the 4x in the batch size making things 4x faster, adjusted for the slower processing.
Now it was time to try with multiple GPUs.
Training on an 8x A100 instance: first steps
I decided to go for the 8x 40GiB/card option that had been available to me previously. That's $10.32/hour. It's strange, but I felt absurdly nervous about maximising usage, and found myself wanting to do everything super-quickly. But while it would cost over $7,000 to keep the machine up and running for a month, taking 2 minutes to do something slowly and carefully rather than rushing through in a blind panic would cost pennies, and would probably save money by leading to fewer mistakes.
Never having run a multi-GPU instance before, I had no idea what to expect; I figured it could go one of four ways:
- CUDA could magically "bind" all of the GPUs together so that it looked like
you had one massive one. This seemed unlikely, but not entirely impossible.
The fact that
nvtopin my home, single-GPU machine, had lines for GPU0 processor and GPU0 RAM usage suggested that it probably wasn't the case. - CUDA might expose all of the cards individually, but PyTorch and/or Transformers might hide that, giving you the same effect as the first option from a developer's perspective.
- The fact that you have multiple GPUs might require code changes on the PyTorch/Transformers side, but they'd have useful libraries to make things reasonably easy.
- You'd have to build your own multi-GPU stuff on top of PyTorch/Transformers.
Now was the moment of truth :-) I logged in, and in nvtop I saw 8 separate
GPUs at the top, with separate memory and processor usage numbers for each:
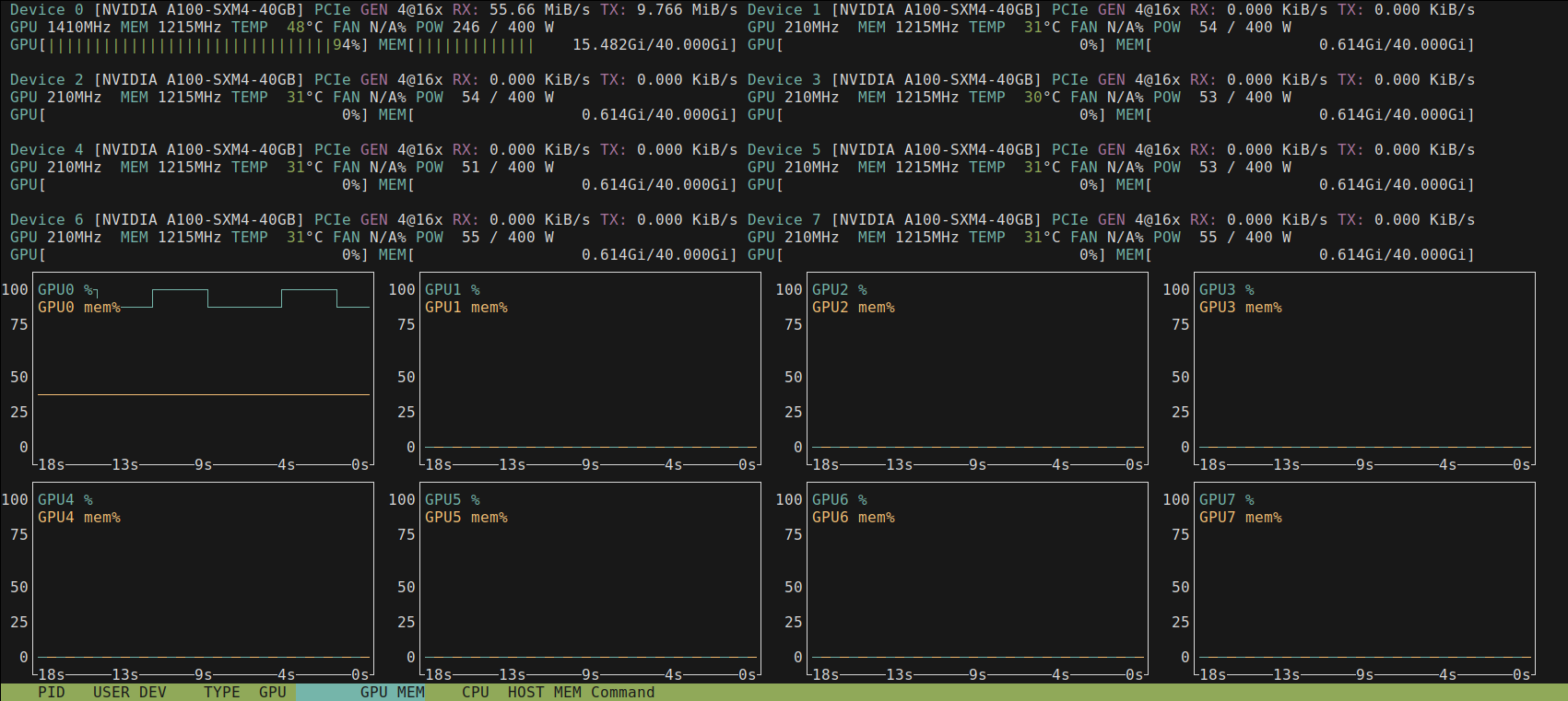
So that strongly suggested that it wasn't unified at the CUDA level. But perhaps the libraries would do the heavy lifting for me? I installed my libraries and cloned my GitHub repo, and then tried running it with 8x the batch size for my previous run on a single A100 -- 4 * 8 = 32.
At the start of the notebook, it loads the model and runs some inference on it.
I could see in nvtop that it was all loaded onto card 0, and in the notebook
it was clear that the speed in tokens/second was basically the same as in the
single-GPU machine.
It then started training... and crapped out when it tried to load more than 40GiB into VRAM. So clearly it was only running on one card. That pretty much showed that we weren't in world #1 or #2 above.
Time to actually RTFD, then. First step: shut down that expensive machine!
Multi-GPU: beginnings
I googled around a bit and quickly came across this useful help page on the Hugging Face site.
They split cases where you need multiple GPUs into three categories:
- Your model fits onto on a GPU.
- Your model doesn't fit onto a GPU (but the layers taken individually do).
- The largest layer in your model is so big that it doesn't fit onto a GPU.
Luckily enough, we're in the first of those cases -- luckily, because it seems overwhelmingly likely that it's the easiest to deal with.
There are three options presented for this case -- DataParallel (DP), DistributedDataParallel (DDP), and ZeRO. I won't recap the differences between them -- they're all well-described in that help page -- but ZeRO seems pretty complicated but very clever; one to look into in the future.
The one that made the most intuitive sense to me is DDP. Essentially we'd just be splitting each batch of 32 into 8 batches of 4, doing an iteration, getting gradients, and averaging them before applying them to the model. That's nice and easy to understand, and I like nice and easy.
Multi-GPU continued: in which ChatGPT is a lot of help /s
However, at this point I did a bit of Q&A with ChatGPT 4 and found out some interesting things about how to run things with DDP. Because its implementation in Transformers is designed to scale not only to multiple GPUs in one machine, but to multiple machines, it's not possible to run it in one process -- you need one process per GPU. The library makes it all pretty simple to do, but it does so by providing a launcher script, which takes a Python script as its parameter. And that would be tricky to do from a notebook.
That information was actually helpful and true.
As a result, I decided to start with DP, because -- at least codewise -- it seemed like it might be much simpler to do. The first step was to take a look at the training code. Let's look at the cell where I set up the arguments:
from transformers import TrainingArguments,Trainer
batch_size = 1
args = TrainingArguments(
'outputs',
learning_rate=8e-5,
warmup_ratio=0.1,
lr_scheduler_type='cosine',
fp16=True,
evaluation_strategy="epoch",
per_device_train_batch_size=batch_size,
per_device_eval_batch_size=batch_size * 2,
num_train_epochs=2,
weight_decay=0.01,
report_to='none'
)
Previously I'd just blindly changed the batch_size to 32. But look at those
parameters further down:
per_device_train_batch_size=batch_size,
per_device_eval_batch_size=batch_size * 2,
"Per device" -- that's pretty clearly something to change! So what, I thought, would happen if I just did this:
from transformers import TrainingArguments,Trainer
batch_size = 32
num_gpus = 8
args = TrainingArguments(
'outputs',
learning_rate=8e-5,
warmup_ratio=0.1,
lr_scheduler_type='cosine',
fp16=True,
evaluation_strategy="epoch",
per_device_train_batch_size=(batch_size // num_gpus),
per_device_eval_batch_size=(batch_size * 2) // num_gpus,
num_train_epochs=2,
weight_decay=0.01,
report_to='none'
)
...? But of course, that would be no different to this:
from transformers import TrainingArguments,Trainer
batch_size = 4
args = TrainingArguments(
'outputs',
learning_rate=8e-5,
warmup_ratio=0.1,
lr_scheduler_type='cosine',
fp16=True,
evaluation_strategy="epoch",
per_device_train_batch_size=batch_size,
per_device_eval_batch_size=batch_size * 2,
num_train_epochs=2,
weight_decay=0.01,
report_to='none'
)
...and we already know that this code on its own wouldn't run things in parallel
across the GPUs. Here's where I started to go down a bit of a rabbit hole.
ChatGPT told me that I'd also need one extra line, to wrap the model
with a DataParallel layer:
from torch.nn import DataParallel
model = DataParallel(model).cuda()
That sounded highly plausible... so it was time to fire up another 8x A100 instance and see what happened. Started it up, installed everything, and then made the changes to the notebook.
The first run failed on the initial inference. The code that we had to load the model was:
from transformers import AutoModelForCausalLM, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained(base_model)
model = AutoModelForCausalLM.from_pretrained(base_model, device_map="cuda")
from torch.nn import DataParallel
model = DataParallel(model).cuda()
...and this, when it tried to run inference on the model, led to an error like this:
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
Cell In[14], line 19
16 tokens_per_second = tokens_generated / time_taken
17 print(f"{tokens_generated} tokens in {time_taken:.2f}s: {tokens_per_second:.2f} tokens/s)")
---> 19 ask_question(model, "Who is Leonardo Da Vinci?")
Cell In[14], line 5, in ask_question(model, question)
4 def ask_question(model, question):
----> 5 pipe = pipeline(task="text-generation", model=model, tokenizer=tokenizer, max_new_tokens=2048)
6 prompt = prompt_template.format(question=question, response="")
7 tokens_in = len(tokenizer(prompt)["input_ids"])
File ~/.virtualenvs/fine-tune/lib/python3.10/site-packages/transformers/pipelines/__init__.py:916, in pipeline(task, model, config, tokenizer, feature_extractor, image_processor, framework, revision, use_fast, token, device, device_map, torch_dtype, trust_remote_code, model_kwargs, pipeline_class, **kwargs)
905 model_classes = {"tf": targeted_task["tf"], "pt": targeted_task["pt"]}
906 framework, model = infer_framework_load_model(
907 model,
908 model_classes=model_classes,
(...)
913 **model_kwargs,
914 )
--> 916 model_config = model.config
917 hub_kwargs["_commit_hash"] = model.config._commit_hash
918 load_tokenizer = type(model_config) in TOKENIZER_MAPPING or model_config.tokenizer_class is not None
File ~/.virtualenvs/fine-tune/lib/python3.10/site-packages/torch/nn/modules/module.py:1688, in Module.__getattr__(self, name)
1686 if name in modules:
1687 return modules[name]
-> 1688 raise AttributeError(f"'{type(self).__name__}' object has no attribute '{name}'")
AttributeError: 'DataParallel' object has no attribute 'config'
On investigation, it became clear that you can't run inference on a DataParallel
wrapper around a model. This makes sense! It's a system for distributing a model
across multiple GPUs so that it can be trained, so it doesn't expose the kind of
things that you need for inference. So, I tried reworking it. The code above
became this:
from transformers import AutoModelForCausalLM, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained(base_model)
model = AutoModelForCausalLM.from_pretrained(base_model, device_map="cuda")
from torch.nn import DataParallel
parallel_model = DataParallel(model).cuda()
...and then I used model for the initial test inference, and passed
parallel_model into the trainer:
trainer = Trainer(
parallel_model, args,
train_dataset=tokenized_dataset['train'],
eval_dataset=tokenized_dataset['test'],
tokenizer=tokenizer,
)
trainer.train()
This lead to a different error during that train -- I won't provide the full stack trace, but the end was this:
File ~/.virtualenvs/fine-tune/lib/python3.10/site-packages/datasets/formatting/formatting.py:527, in _check_valid_index_key(key, size)
525 if isinstance(key, int):
526 if (key < 0 and key + size < 0) or (key >= size):
--> 527 raise IndexError(f"Invalid key: {key} is out of bounds for size {size}")
528 return
529 elif isinstance(key, slice):
IndexError: Invalid key: 8710 is out of bounds for size 0
That looked like it was coming out of the dataset.
Now, at this point I could feel the costs racking up on the big GPU instance. But there didn't seem to be any reason why I wouldn't get the same error by running the same training run locally; presumably the same issues would arise whether I was doing DP training on one GPU as did with multiple. So I figured it was time to shut down this 8x instance, make the changes locally, and see if the issue repro'd.
Highly usefully, it did! Now, without the ticking clock of money being spent on
an expensive rented computer, I could dig in to what was going on. I created a
new third-0.5b-fine-tune-with-dp.ipynb
notebook, trimmed out the data exploration
stuff, and kept just the training, with the changes from earlier.
I spent some time banging my head against the issue, both normal debugging, and futher
Q&A with ChatGPT. With the latter, I started feeling very suspicious after a
while. ChatGPT
was telling me that all I needed to do was wrap the model in DataParallel, and
train on that. I provided it with the full code I was running and the error I was getting, and
its response was effectively "that's odd, that should work!" When queried on
possible causes of the error, it started generating really unlikely possibilities
-- not quite to the level of "cosmic rays are flipping the bits in your RAM", but
things that intuitively didn't make sense.
I'm beginning to feel that this is a pattern that you can use to recognise a hallucinated API or other piece of techical advice from generative AI. If it says "you just need to do X", and X doesn't work, if you then provide it with minimal code showing that X doesn't work and it starts sounding like it's making excuses, you've been hallucinated to.
Multi-GPU moves on: in which I returned to the straight and narrow
I figured that this was probably the right time to start asking other people for help; perhaps there was something really simple I was missing, or perhaps, as I suspected, ChatGPT had been leading me down a blind alley with hallucinated code. I posted in the Hugging Face forums to see if anyone had any thoughts.
There was silence, however, so it was time to look for more information. I discovered this page. It's the docs for a library built on top of Transformers, called Transformers4Rec, but it says:
To use the DataParallel mode training, user just needs to make sure
CUDA_VISIBLE_DEVICESis set. For example when 2 GPUs are available:Add
os.environ["CUDA_VISIBLE_DEVICES"]="0,1"to the script
"I wonder if Transformers uses something similar", I thought. And right at the bottom of the HF help page I'd been looking at earlier, I found this section on GPU selection, saying that you should use the same thing. Argh! A bit too hidden, if you ask me.
Still, worth a try. Logging in to Lambda Labs, I found a 2x A100 instance available, which looked like a great choice for testing this out. I didn't want to change the notebook I had linked to from my Hugging Face forum post, so in a fork of it, I added the environment variable setting and kicked it off on the two-GPU machine.
No luck -- the same error when trying to train the parallel_model, and a single-GPU
train started when I tried to train the model.
At this stage, I felt that my decision to only try the training run in a notebook
was likely to be what was holding me back. Further checking of the HF help page
showed that the environment variable was in a documentation section using a
torchrun command to launch the script. And the DDP option would also be using
a launcher to run it. So, I thought, let's work within the system, and assume that ChatGPT's
suggested code was a hallucination.
I created a version of my third "test" notebook as a script,
confirmed that I could run it with torchrun locally:
torchrun third-0.5b-fine-tune-as-script.py
It ran just fine, so I spun up that 2x instance again. I cloned the repo, installed the things, and:
(fine-tune) ubuntu@104-171-203-114:~/fine-tune-2024-04$ torchrun third-0.5b-fine-tune-as-script.py
Downloading readme: 100%|================================================================================================================| 395/395 [00:00<00:00, 2.00MB/s]
Repo card metadata block was not found. Setting CardData to empty.
Downloading data: 100%|==============================================================================================================| 20.9M/20.9M [00:00<00:00, 83.8MB/s]
Downloading data: 100%|==============================================================================================================| 1.11M/1.11M [00:00<00:00, 6.60MB/s]
Generating train split: 100%|==============================================================================================| 9846/9846 [00:00<00:00, 135090.34 examples/s]
Generating test split: 100%|==================================================================================================| 518/518 [00:00<00:00, 66035.97 examples/s]
tokenizer_config.json: 100%|=========================================================================================================| 1.29k/1.29k [00:00<00:00, 5.27MB/s]
vocab.json: 100%|====================================================================================================================| 2.78M/2.78M [00:00<00:00, 35.4MB/s]
merges.txt: 100%|====================================================================================================================| 1.67M/1.67M [00:00<00:00, 5.80MB/s]
tokenizer.json: 100%|================================================================================================================| 7.03M/7.03M [00:00<00:00, 39.9MB/s]
Special tokens have been added in the vocabulary, make sure the associated word embeddings are fine-tuned or trained.
config.json: 100%|=======================================================================================================================| 661/661 [00:00<00:00, 3.26MB/s]
model.safetensors: 100%|==============================================================================================================| 1.24G/1.24G [00:03<00:00, 405MB/s]
generation_config.json: 100%|=============================================================================================================| 138/138 [00:00<00:00, 718kB/s]
Map: 100%|===================================================================================================================| 9846/9846 [00:08<00:00, 1143.44 examples/s]
Map: 100%|=====================================================================================================================| 518/518 [00:00<00:00, 1179.78 examples/s]
0%| | 0/19692 [00:00<?, ?it/s]
[rank0]:[W reducer.cpp:1360] Warning: find_unused_parameters=True was specified in DDP constructor, but did not find any unused parameters in the forward pass. This flag results in an extra traversal of the autograd graph every iteration, which can adversely affect performance. If your model indeed never has any unused parameters in the forward pass, consider turning this flag off. Note that this warning may be a false positive if your model has flow control causing later iterations to have unused parameters. (function operator())
1%|=
Once again, nvtop showed that it was only running with one GPU. But that thing
about DDP was interesting! I tried adding the environment variable:
(fine-tune) ubuntu@104-171-203-114:~/fine-tune-2024-04$ CUDA_VISIBLE_DEVICES=0,1 torchrun third-0.5b-fine-tune-as-script.py
Repo card metadata block was not found. Setting CardData to empty.
Special tokens have been added in the vocabulary, make sure the associated word embeddings are fine-tuned or trained.
0%| | 0/19692 [00:00<?, ?it/s]
[rank0]:[W reducer.cpp:1360] Warning: find_unused_parameters=True was specified in DDP constructor, but did not find any unused parameters in the forward pass. This flag results in an extra traversal of the autograd graph every iteration, which can adversely affect performance. If your model indeed never has any unused parameters in the forward pass, consider turning this flag off. Note that this warning may be a false positive if your model has flow control causing later iterations to have unused parameters. (function operator())
1%|▋
One GPU again. Boo! But running it just with python had an interesting difference:
(fine-tune) ubuntu@104-171-203-114:~/fine-tune-2024-04$ python third-0.5b-fine-tune-as-script.py
Repo card metadata block was not found. Setting CardData to empty.
Special tokens have been added in the vocabulary, make sure the associated word embeddings are fine-tuned or trained.
0%|▏
That stuff about DDP wasn't there at all. Finally, I noticed the important bit in the docs -- you have to tell torchrun how many processes to use per node, which in effect tells it how many cards to use. So, off we go again:
(fine-tune) ubuntu@104-171-203-114:~/fine-tune-2024-04$ torchrun --nproc_per_node=2 third-0.5b-fine-tune-as-script.py
[2024-05-13 20:06:32,405] torch.distributed.run: [WARNING]
[2024-05-13 20:06:32,405] torch.distributed.run: [WARNING] *****************************************
[2024-05-13 20:06:32,405] torch.distributed.run: [WARNING] Setting OMP_NUM_THREADS environment variable for each process to be 1 in default, to avoid your system being overloaded, please further tune the variable for optimal performance in your application as needed.
[2024-05-13 20:06:32,405] torch.distributed.run: [WARNING] *****************************************
Repo card metadata block was not found. Setting CardData to empty.
Repo card metadata block was not found. Setting CardData to empty.
Special tokens have been added in the vocabulary, make sure the associated word embeddings are fine-tuned or trained.
Special tokens have been added in the vocabulary, make sure the associated word embeddings are fine-tuned or trained.
0%| | 0/9846 [00:00<?, ?it/s]
[rank1]:[W reducer.cpp:1360] Warning: find_unused_parameters=True was specified in DDP constructor, but did not find any unused parameters in the forward pass. This flag results in an extra traversal of the autograd graph every iteration, which can adversely affect performance. If your model indeed never has any unused parameters in the forward pass, consider turning this flag off. Note that this warning may be a false positive if your model has flow control causing later iterations to have unused parameters. (function operator())
[rank0]:[W reducer.cpp:1360] Warning: find_unused_parameters=True was specified in DDP constructor, but did not find any unused parameters in the forward pass. This flag results in an extra traversal of the autograd graph every iteration, which can adversely affect performance. If your model indeed never has any unused parameters in the forward pass, consider turning this flag off. Note that this warning may be a false positive if your model has flow control causing later iterations to have unused parameters. (function operator())
0%|
Hooray!!! It worked, and I was seeing activity in both GPUs.
Weirdly, though, it was training more slowly and was using up less than half the VRAM. But I spotted that the batch size in my script was one -- I had reverted it while running the previous experiments. Ooops! Bumped that up to 4 again, but it ran out of memory. Perhaps there's an extra RAM usage for multi-GPU training?
I dropped it to three, and this time things were looking pretty good. At this point,
it was running at 2.62s per iteration, and had
an expected runtime of about 22 minutes. I decided I'd let that run. I noticed
that it was using 37.97GiB of VRAM on GPU0 and 35.17 on GPU1, which was interesting
-- I'd got the impression that GPU0 was "special" in DP, but not in DDP. However,
looking at the list of processes in nvtop explained that -- there were three
processes running, one using about 3.8GiB, and two using about 35GiB. My guess
was that the extra process was some kind of "control" process, and it was running on
GPU0. Perhaps it was storing the version of the model that the combined gradients
from the models that were training were being applied to, before they were copied
back to the other processes?
Unfortunately, halfway through it crapped out -- it ran out of RAM again. It looked like the end-of-epoch benchmarking was too much for it. Batch size down to 2? But it didn't sound worth it with this training script.
Instead, I decided to run the script again with python -- and found, pretty
much as expected, that it was using less memory, 75% of one GPU rather than >85%
of both --it makes sense that there's a multi-GPU overhead. It was estimating
38 minutes to completion, which was near enough the time training on the single
GPU machine earlier.
The next thing was to see how it scaled; I wanted to find out whether -- given a fixed batch size -- the time to train scaled smoothly with the number of GPUs, or if there was some kind of dropoff.
Let's plot it!
I decided that I'd run a careful, methodical test. I'd run the training script with a batch size of one, and then make note of the iterations per second, the number of iterations needed, and the estimated time to completion (snapshotted at 2% training completion). I'd also take a look at the processes running and try to work out what was happening with VRAM consumption.
I'd do that running under python, and
also for torchrun with 1, 2, 3, 4, 5, 6, 7 and 8 processes. I needed an 8-GPU
machine for this, so I spun one up.
Here's what I got:
| Launcher | # processes | iterations/sec | total iterations | time (mins) | VRAM usage |
|---|---|---|---|---|---|
| python | 1 | 6.24 | 19692 | 52 | 15.4GiB on GPU0 |
| torchrun | 1 | 5.81 | 19692 | 56 | 16.8GiB on GPU0 |
| torchrun | 2 | 5.48 | 9846 | 30 | 17.4GiB on each GPU, 1 extra at 2.8GiB on GPU0 |
| torchrun | 3 | 5.39 | 6564 | 20 | 17.6GIB on each GPU, 2 extra at 2.8GiB on GPU0 |
| torchrun | 4 | 5.38 | 4924 | 15 | 17.7GiB on each GPU, 3 extra at 2.8GiB on GPU0 |
| torchrun | 5 | 5.33 | 3940 | 12 | 17.7GiB on each GPU, 4 extra at 2.8GiB on GPU0 |
| torchrun | 6 | 5.32 | 3282 | 10 | 17.7GiB on each GPU, 5 extra at 2.8GiB on GPU0 |
| torchrun | 7 | 5.30 | 2814 | 9 | 17.7GiB on each GPU, 6 extra at 2.8GiB on GPU0 |
| torchrun | 8 | 5.29 | 2462 | 8 | 17.7GiB on each GPU, 7 extra at 2.8GiB on GPU0 |
Timewise, that looks exactly what we'd
expect from a smoothly scaling system. Going from python to torchrun has an
immediate cost, but once you've done that, each additional GPU only adds on a
small overhead in terms of iterations/sec, so that (for example) doubling the number of GPUs almost halves
the time taken. You can see that slighly better in these plots:
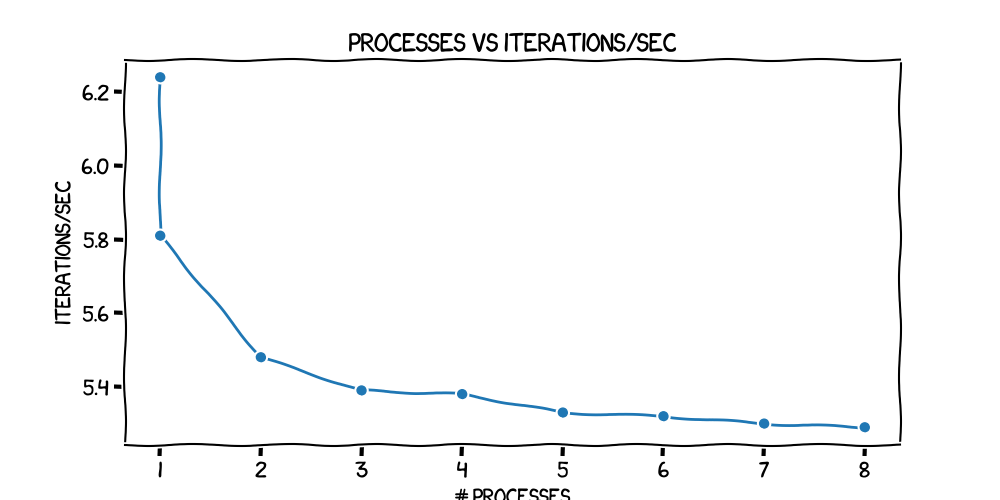
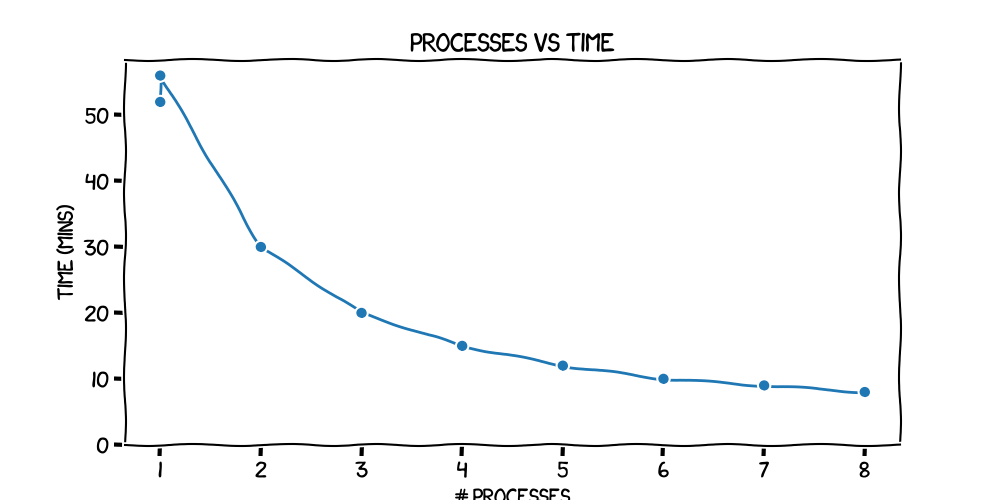
Note to anyone else that likes xkcd plots: the pyplot code for those two is here.
The VRAM usage was interesting, though. It looked like there was a small increase in per-GPU VRAM at each step up to 4 processes, at which it capped out. However, as soon as there were two GPUs involved, an extra process appeared on GPU0 -- the one that I was thinking might be some kind of "control" process. But more of these kept appearing, so that the total number was always num_gpus - 1. And they all wound up on GPU0.
That definitely sounded like it would benefit from further investifation. But I felt that it was time to wrap this one up.
So, what have we learned?
So, great! I had a fully-functioning multi-GPU training setup for the small model that I'd been using so far. I'd learnt a lot and taken some interesting measurements that pointed towards further things to study.
I'd found that:
- Extra VRAM really helps with training time, because of the larger batch size it makes possible.
- Multi-GPU training is significantly more complex than single-GPU, and not really possible to do inside a notebook. You need a
script so that you can launch it with
torchrun. The libraries help out, but not to the extent that it's transparent. In terms of the four different ways I thought multiple GPUs could be exposed to the developer, we were somewhere between #3 and #4. - There is a small performance penalty in terms of iterations/second each time you increase the number of GPUs
- This slowdown wasn't enough to change the fact that the time required for training goes down pretty much proportionally with the number of GPUs.
- Switching to multi-GPU increases the memory footprint; there's a one-off cost simply in switching to DDP, and then smallish increases per-GPU up to 4.
- But on top of that, there's an extra process running on GPU0 for each GPU you add from the second one onwards. That suggests a limit to scaling that way.
What next?
Next steps
At this point, I think it's time to switch over to trying to train the larger model. I had hoped that I would be pretty confident that it would work with essentially the same setup as I had been using this time around, but it looks to me like there's one important difference.
Right back at the beginning of this journey, I found a resource suggesting that you need about 160GiB of VRAM to train a 7B model; the 8x A100 instance I've been using has 320GiB, so that should be ample. But: with this tiny 0.5B parameter model, with a batch size of one, we were using about 50% of the VRAM on all of the GPUs with DDP, and we were using almost the remaining 50% on GPU0 because of those extra processes.
What these experiments did was use parallelisation to speed up the training. They didn't find out how to use parallelisation to make use of the extra VRAM available in the other cards. The HF page I was basing my experiments on had its three categories:
- Your model fits onto on a GPU.
- Your model doesn't fit onto a GPU (but the layers taken individually do).
- The largest layer in your model is so big that it doesn't fit onto a GPU.
I'd taken that as meaning "your model can be loaded onto a GPU" -- that is, roughly speaking, it has 2 GiB of VRAM for each billion parameters, plus a bit of overhead -- the amount that's needed for inference. I've started to feel from these experiments that they might have meant "can be trained on a single GPU", which is very different -- as we know from the numbers above, even without the DDP parallelism overhead, our 0.5B model takes up over 15GiB VRAM for training with a batch size of one.
I think the best way to move on with this is going to be to bite the bullet, try to train the 8B model, and see what happens. I suspect I'm going to be learning a lot about the other strategies on that help page soon.