Messing around with fine-tuning LLMs, part 8 -- detailed memory usage across batch sizes
This is the 8th installment in a mammoth project that I've been plugging away at since April. My goal is to fine-tune an 8B model -- specifically, the Llama 3 8B base model -- on the openassistant-guanaco dataset, without using tricks like quantization or LoRA. I'm doing this as a way to try to understand how to do full-on multi-GPU training of a model that cannot be trained on just one GPU -- so I'm taking it super-slowly and stopping and measuring everything along the way.
So far, I've:
- Fine-tuned a 0.5B model on my own machine.
- Done the same, but in the cloud using Lambda Labs.
- Run some multi-GPU training, but using the GPUs to run larger batches for the 0.5B model -- which in turn means training faster -- rather than to train a larger model.
- Successfully fine-tuned the 8B model across multiple GPUs using ZeRO and DeepSpeed, but with the optimizer offloaded to CPU.
- Done some initial experiments into memory usage for a 0.5B model locally to get some ideas as to why I had to offload the optimizer.
- Measured memory usage more systematically for the 0.5B model, also locally, to find out how it behaves with different sequence lengths.
- Made similar measurements for the 8B model.
I'd reached the conclusion that the only safe way to find out how much memory a fine-tune of either of the models I was working with would use was just to try it. The memory usage was important for three reasons -- firstly, whether the model could be trained at all on hardware I had easy access to, secondly, if it could be trained, whether I'd need to offload the optimizer (which had a serious performance impact), and thirdly what the batch size would be -- larger batches mean much better training speed.
This time around I wanted to work out how much of an impact the batch size would have -- how does it affect memory usage and speed? I had the feeling that it was essentially linear, but I wanted to see if that really was the case.
Here's what I found.
Messing around with fine-tuning LLMs, part 7 -- detailed memory usage across sequence lengths for an 8B model
My goal is to fine-tune an 8B model -- specifically, the Llama 3 8B base model -- on the openassistant-guanaco dataset, without using tricks like quantization or LoRA. I'm doing this as a way to try to understand how to do full-on multi-GPU training of a model that cannot be trained on just one GPU.
I've been building up to this goal gradually; so far, I've:
- Fine-tuned a 0.5B model on my own machine.
- Done the same, but in the cloud using Lambda Labs.
- Run some multi-GPU training, but using the GPUs to run larger batches for the 0.5B model -- which in turn means training faster -- rather than to train a larger model.
- Successfully fine-tuned the 8B model across multiple GPUs using ZeRO and DeepSpeed, but with the optimizer offloaded to CPU.
- Done some initial experiments into memory usage for a 0.5B model locally to get some ideas as to why I had to offload the optimizer.
- Measured memory usage more systematically for the 0.5B model, also locally, to find out how it behaves with different sequence lengths.
My tentative conclusion from the last post was that perhaps the function I was using
to estimate per-GPU memory usage, estimate_zero3_model_states_mem_needs_all_live,
might be accurate with a sequence length of 1. Right back at
the start of these experiments, I'd realised that the
sequence length is an important factor when
working out RAM requirements, and the function didn't take it as a parameter --
which, TBH, should have made it clear to me from the start that it didn't have
enough information to estimate numbers for fine-tuning an LLM.
In my last experiments, I measured the memory usage when training the 0.5B model at different sequence lengths and found that it was completely flat up to iteration 918, then rose linearly. Graphing those real numbers against a calculated linear approximation for that second segment gave this ("env var" in the legend refers to the environment variable to switch on expandable segments, about which much more later -- the blue line is the measured allocated memory usage):
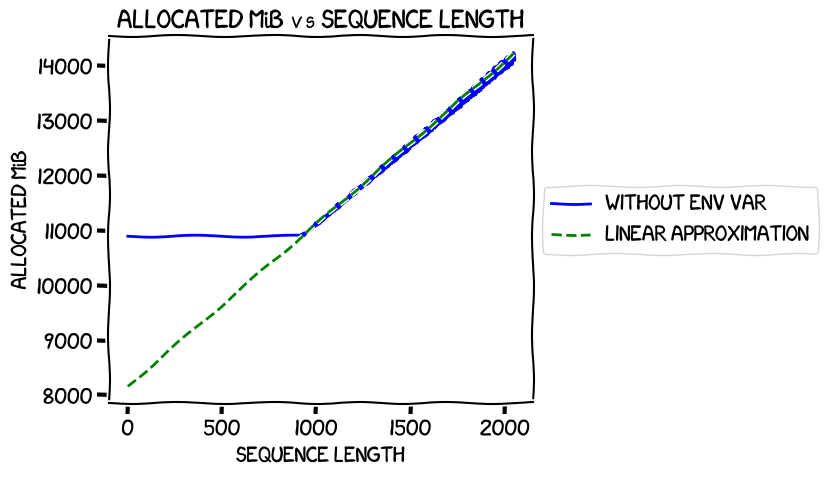
It intersected the Y axis at around 8 GiB -- pretty much the number estimated
by estimate_zero3_model_states_mem_needs_all_live.
So, this time around I wanted to train the 8B model, and see if I got the same kind of results. There were two variables I wanted to tweak:
- Expandable segments. Setting the environment variable
PYTORCH_CUDA_ALLOC_CONFtoexpandable_segments:Truehad reduced the memory usage of the training quite significantly. After some initial confusion about what it did, I had come to the conclusion that it was a new experimental way of managing CUDA memory, and from the numbers I was seeing it was a good thing: lower memory usage and slightly better performance. I wanted to see if that held for multi-GPU training. - Offloading the optimizer. I had needed to do that for my original successful fine-tune of the 8B model because not doing it meant that I needed more than the 40 GiB I had available on each of the 8 GPUs on the machine I was using. What was the impact of using it on memory and performance?
So I needed to run four tests, covering the with/without expandable segments and with/without optimizer offload. For each test, I'd run the same code as I did in the last post, measuring the numbers at different sequence lengths.
Here's what I found.