3D graphics in Resolver One using OpenGL and Tao, part II: an orrery
In my last post about animated 3D graphics in Resolver One (the souped-up spreadsheet the company I work for makes), I showed a bouncing, spinning cube controlled by the numbers in a worksheet. Here's something more sophisticated: a 3D model of the planets in our solar system, also know as an orrery (click the image for video):
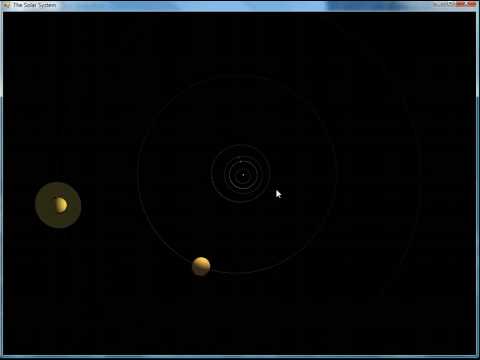 :
:
3D graphics in Resolver One using OpenGL and Tao, part I
I've been playing around with 3D graphics recently, and decided to find out what could be done using .NET from inside Resolver One. (If you haven't heard of Resolver One, it's a spreadsheet made by the company I work for -- think of it as Excel on steroids :-)
I was quite pleased at what I managed with a few hours' work (click the image for video):
Fix for pygame/PyOpenGL/NeHe tutorial windows not disappearing when run from IDLE
It's a long weekend here in the UK and I thought I'd spend some time working through Paul Furber's Python translations of the well-known NeHe OpenGL tutorial, which use the pygame and PyOpenGL libraries. (This is all with Python 2.6 on Windows XP.)
I noticed that when I ran the sample files from IDLE, the windows did not close -- it didn't matter whether I used the close box or hit escape; the program would seem to exit, but IDLE was in a messy state, and the OpenGL window would sit there not repainting.
Googling didn't turn up anything that sounded relevant, but this archived mailing list message
mentioned a pygame.quit() function that sounded relevant. I tried putting this
at the end of each of the samples, and it seems to fix the problem.
Ada Lovelace day
I'm a day late, but having just heard about Ada Lovelace day I couldn't but help make a slightly schmalzy post.
The aim of the day is to celebrate women who excel in technology, and while I've worked with some great women developers over the course of my career, there's one who stands out. Yes, it's my mother :-)
Back in the 60s, Yvonne Thomas was one of the first women to do Electronic Engineering (or Electron Physics as it was then called) at Southampton University, and she went on to work at various defence-related companies (that being the best place to be in tech back then). By 1974 she was working on ALGOL compilers at (I think) ICL, and then she decided to pack it in to raise her unruly -- but generally grateful -- offspring. Von, thanks for doing that, and for bringing me up to be technically able. There are few coders out there who can honestly say that they had programming fed to them in the womb, and I'm glad to be one of them.
She's still coding, and is now happily building an ever-expanding web application that links together all the information she's found in her genealogical researches.
Right, enough sentimentality. Back to our regularly-scheduled gadget- and business-of-software-related blogging...
R in Resolver One (and perhaps IronPython generally)
We've just announced the winner of this month's round of our competition at Resolver Systems, and it's a great one; Marjan Ghahremani, a student at UC Davis, managed to work out how you can call R (a powerful statistical analysis language) from our spreadsheet product Resolver One. You can download a ZIP file with a detailed PDF describing how it works and a bunch of examples.
If you're not interested in Resolver One, but want to use R from your own IronPython scripts, you may be able to do that too, using her instructions as guidelines -- I've not tried it myself, but there are no obvious blockers. If you do try it out, I'd love to hear how it goes.
xmlrpc
One of our customers had been asking about how to call XMLRPC servers from
Resolver One. It doesn't work in version 1.3, and he was having problems getting
it to work in 1.4. The problem turned out to be simple and fixable, and unlikely
to affect other people, so I'm proud to present a really simple XMLRPC/Resolver One example
that you can use as a starting point: a Python script that creates a server
exposing an is_even function (which tells you if a number is even or not), and
a Resolver One spreadsheet that uses it. There are only two lines of code in
the spreadsheet, which is pretty cool :-)
Getting phpBB to accept Django sessions
phpBB is a fantastic bulletin board system. We use it at Resolver Systems for our forums, and it does a great job.
However, we're a Python shop, so we prefer to do our serious web development -- for example, the login system that allows our paying customers to download fully-featured unlocked versions of our software -- in Django.
We needed to have a single sign-on system for both parts of our website. Specifically, we wanted people to be able to log in using the Django authentication module, and then to be able to post on the forums without logging in again. This post is an overview of the code we used; I've had to extract it from various sources, so it might not be complete -- let me know in the comments if anything's missing.
VAT calculations
There's been an interesting discussion over at Smurf on Spreadsheets about the consequences of the UK government's temporary VAT rate reduction. For the benefit of non-UK readers, VAT is basically the british sales tax (it differs a little in implementation from a simple sales tax). It is currently 17.5%, but as a reaction to the financial crisis, it will be reduced to 15% from 1 December 2008 until 31 January 2010 inclusive. Whether this makes sense as a matter of economic policy is, of course, highly contentious. But this is a technical blog so I'll stick to its effect on spreadsheets :-)
Ironclad 0.7 released
Excellent news from my friend and colleague William -- he's released version 0.7 of our Ironclad project, a library that allows you to use the useful C extensions that have been written for CPython (Python's reference implementation) from within IronPython (Microsoft's version for .NET -- the version we use at Resolver Systems).
William has many caveats about how far there still is to go, but this new release is tantalisingly close to being ready for alpha testing. Huge chunks of numpy, the numerical Python library for doing difficult maths with large data sets, now work. This is fantastic stuff -- close enough that we're now seriously considering having it as an option (with an explicit note that it's not ready for production use) in the next release of Resolver One -- or at least the one after that.
[Update] The redoubtable Michael Foord, another friend and colleague, has written a much better and more detailed post about this release on the IronPython URLs blog.
Why use IronPython?
I just posted this on the Joel on Software discussion board, in answer to someone's question about using IronPython for their new company. Hopefully it will be of interest here.
We've been using IronPython for three years now with a lot of success. The great thing about it is that it allows you to benefit from Python's syntax while getting most of the advantages of .NET:
- All of the .NET libraries are available.
- UIs look nice. I've never seen a pure traditional Python application that looked good, no matter how advanced its functionality.
- We use a bunch of third-party components -- for example, Syncfusion's Essential Grid -- without any problems.
- Reasonably decent multithreading using the .NET libraries -- CPython, the normal Python implementation, has the problem of the Global Interpreter Lock, an implementation choice that makes multithreading dodgy at best.
- We can build our GUI in Visual Studio, and then generate C# classes for each dialog, and then subclass them from IronPython to add behaviour. (We never need to look at the generated code.)
- When things go wrong, the CLR debugger works well enough -- it's not perfect, but we've never lost a significant amount of time for want of anything better.
Of course, it's not perfect. Problems versus using C#:
- It's slower, especially in terms of startup time. They are fixing this, but it's a problem in the current release. This hasn't bitten us yet -- all of the non-startup-related performance issues we've had have been due to suboptimal algorithms rather than language speed. However, it you're writing something that's very performance-intensive, you may want to look elsewhere.
- No LINQ yet.
- If you're considering IP then you presumably already know this, but dynamic languages have no compile-time to perform sanity checks on your codebase, so problems can come up at runtime. We write all of our code test-first and so we aren't impacted by that. However, if you're not writing a solid amount of test code (and if you're not, you should :-) then you might want to use a statically-typed language.
Problems versus using CPython:
- No cross-platform. Linux or Mac support is one of our more frequently-requested enhancements, and it will be a lot of work to add. The reason for this is that many third-party .NET components -- for example, the Synfusion grid -- are not "pure" .NET; they drop into win32 for certain operations, I assume for performance reasons. This means that if you use them, your application won't run on non-Windows .NET platforms.
- No use of CPython's C extensions, like numpy (a numerical functions library). This has hit us pretty hard, so we're working on an open-source library to interface between C extensions and IronPython -- however, it's still a work in progress.
Hope this was of some help.