Messing around with fine-tuning LLMs, part 9 -- gradient checkpointing
This is the 9th installment in my ongoing investigations into fine-tuning LLM models. My goal is to fine-tune an 8B model -- specifically, the Llama 3 8B base model -- on the openassistant-guanaco dataset, without using tricks like quantization or LoRA. I'm doing this as a way to try to understand how to do full-on multi-GPU training of a model that cannot be trained on just one GPU -- so I'm taking it super-slowly and stopping and measuring everything along the way, which means that I'm learning a ton of new stuff pretty effectively.
So far, I've:
- Fine-tuned a 0.5B model on my own machine.
- Done the same, but in the cloud using Lambda Labs.
- Run some multi-GPU training, but using the GPUs to run larger batches for the 0.5B model -- which in turn means training faster -- rather than to train a larger model.
- Successfully fine-tuned the 8B model across multiple GPUs using ZeRO and DeepSpeed, but with the optimizer offloaded to CPU.
- Done some initial experiments into memory usage for a 0.5B model locally to get some ideas as to why I had to offload the optimizer.
- Measured memory usage more systematically for the 0.5B model, also locally, to find out how it behaves with different sequence lengths.
- Made similar measurements at different sequence lengths for the 8B model.
- Measured the effect of batch sizes on memory usage, with a sidetrack into looking at Liger Kernel, a new and easy-to use replacement of the default CUDA kernels used for training that promises (and delivers) better memory usage and performance.
I'll look into Liger in more depth in a future post, because it looks incredibly useful, but first I wanted to investigate something that I learned about as a result of my original post about it. I posted my results on X, and Byron Hsu (who's building Liger at LinkedIn) thought it was weird that I was only able to squeeze a batch size of two (without Liger) or three (with it) into an 8x A100 80 GiB machine. In the Liger GitHub repo, they have an example of the kind of memory improvements the new kernels can provide; it shows without-Liger memory usages of (roughly) 55 GiB at a batch size of 32, 67 GiB at 48, and an OOM with 64. Now, they're using a sequence length of 512 rather than the 2048 I've been using, and that would have an effect, but not enough to allow batches that were sixteen times larger -- expecially because their benchmarks were being run on a machine with four A100 80 GiB cards, not eight.
Byron and I had a quick chat just to see if there was anything obviously dumb going on in my configuration, and one thing that stood out to him was that I wasn't using gradient checkpointing (which the Liger example is doing). That was something I'd very briefly looked into back in my earliest experiments into tuning the 8B model; I was following a Hugging Face guide to what to do if you hit memory problems. In their guide to DeepSpeed, they write:
A general process you can use is (start with batch size of 1):
- enable gradient checkpointing
- try ZeRO-2
- try ZeRO-2 and offload the optimizer
I had tried running my tune with both the gradient checkpointing enabled and Zero-2, but it blew up at iteration 24 (my first indication that there was something that kicked in at that point that increased memory usage), so I'd moved straight on to the optimizer offload.
At that point I was using instances with 8x A100 40 GiB. Since then, I'd switched to using 80 GiB per GPU machines, and done various tests comparing performance:
- With no gradient checkpointing, ZeRO 3 and no optimizer offload, versus
- With gradient checkpointing, ZeRO 2, and the optimizer offloaded.
But what would happen if I just tried Zero 3 with no optimizer offload, with and without gradient checkpointing? That really sounded worth a look.
So, while I finished off my last post by saying
I think I'm finally in a place where I can do what should be the last experiment in this series: a full fine-tune of the Llama 3 8B base model -- on the openassistant-guanaco dataset, without using tricks like quantization or LoRA.
...it now looks like there's something well worth investigating first: gradient checkpointing.
Messing around with fine-tuning LLMs, part 8 -- detailed memory usage across batch sizes
This is the 8th installment in a mammoth project that I've been plugging away at since April. My goal is to fine-tune an 8B model -- specifically, the Llama 3 8B base model -- on the openassistant-guanaco dataset, without using tricks like quantization or LoRA. I'm doing this as a way to try to understand how to do full-on multi-GPU training of a model that cannot be trained on just one GPU -- so I'm taking it super-slowly and stopping and measuring everything along the way.
So far, I've:
- Fine-tuned a 0.5B model on my own machine.
- Done the same, but in the cloud using Lambda Labs.
- Run some multi-GPU training, but using the GPUs to run larger batches for the 0.5B model -- which in turn means training faster -- rather than to train a larger model.
- Successfully fine-tuned the 8B model across multiple GPUs using ZeRO and DeepSpeed, but with the optimizer offloaded to CPU.
- Done some initial experiments into memory usage for a 0.5B model locally to get some ideas as to why I had to offload the optimizer.
- Measured memory usage more systematically for the 0.5B model, also locally, to find out how it behaves with different sequence lengths.
- Made similar measurements for the 8B model.
I'd reached the conclusion that the only safe way to find out how much memory a fine-tune of either of the models I was working with would use was just to try it. The memory usage was important for three reasons -- firstly, whether the model could be trained at all on hardware I had easy access to, secondly, if it could be trained, whether I'd need to offload the optimizer (which had a serious performance impact), and thirdly what the batch size would be -- larger batches mean much better training speed.
This time around I wanted to work out how much of an impact the batch size would have -- how does it affect memory usage and speed? I had the feeling that it was essentially linear, but I wanted to see if that really was the case.
Here's what I found.
Messing around with fine-tuning LLMs, part 7 -- detailed memory usage across sequence lengths for an 8B model
My goal is to fine-tune an 8B model -- specifically, the Llama 3 8B base model -- on the openassistant-guanaco dataset, without using tricks like quantization or LoRA. I'm doing this as a way to try to understand how to do full-on multi-GPU training of a model that cannot be trained on just one GPU.
I've been building up to this goal gradually; so far, I've:
- Fine-tuned a 0.5B model on my own machine.
- Done the same, but in the cloud using Lambda Labs.
- Run some multi-GPU training, but using the GPUs to run larger batches for the 0.5B model -- which in turn means training faster -- rather than to train a larger model.
- Successfully fine-tuned the 8B model across multiple GPUs using ZeRO and DeepSpeed, but with the optimizer offloaded to CPU.
- Done some initial experiments into memory usage for a 0.5B model locally to get some ideas as to why I had to offload the optimizer.
- Measured memory usage more systematically for the 0.5B model, also locally, to find out how it behaves with different sequence lengths.
My tentative conclusion from the last post was that perhaps the function I was using
to estimate per-GPU memory usage, estimate_zero3_model_states_mem_needs_all_live,
might be accurate with a sequence length of 1. Right back at
the start of these experiments, I'd realised that the
sequence length is an important factor when
working out RAM requirements, and the function didn't take it as a parameter --
which, TBH, should have made it clear to me from the start that it didn't have
enough information to estimate numbers for fine-tuning an LLM.
In my last experiments, I measured the memory usage when training the 0.5B model at different sequence lengths and found that it was completely flat up to iteration 918, then rose linearly. Graphing those real numbers against a calculated linear approximation for that second segment gave this ("env var" in the legend refers to the environment variable to switch on expandable segments, about which much more later -- the blue line is the measured allocated memory usage):
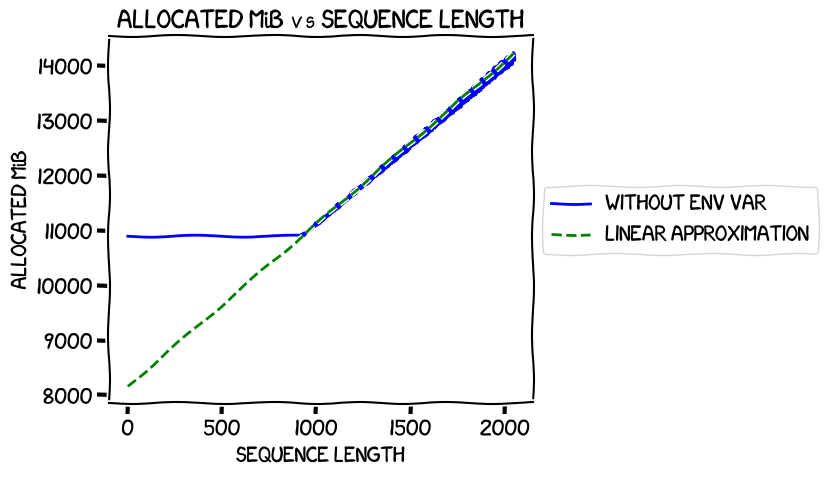
It intersected the Y axis at around 8 GiB -- pretty much the number estimated
by estimate_zero3_model_states_mem_needs_all_live.
So, this time around I wanted to train the 8B model, and see if I got the same kind of results. There were two variables I wanted to tweak:
- Expandable segments. Setting the environment variable
PYTORCH_CUDA_ALLOC_CONFtoexpandable_segments:Truehad reduced the memory usage of the training quite significantly. After some initial confusion about what it did, I had come to the conclusion that it was a new experimental way of managing CUDA memory, and from the numbers I was seeing it was a good thing: lower memory usage and slightly better performance. I wanted to see if that held for multi-GPU training. - Offloading the optimizer. I had needed to do that for my original successful fine-tune of the 8B model because not doing it meant that I needed more than the 40 GiB I had available on each of the 8 GPUs on the machine I was using. What was the impact of using it on memory and performance?
So I needed to run four tests, covering the with/without expandable segments and with/without optimizer offload. For each test, I'd run the same code as I did in the last post, measuring the numbers at different sequence lengths.
Here's what I found.
Messing around with fine-tuning LLMs, part 6 -- measuring memory usage more systematically
My goal is to fine-tune an 8B model -- specifically, the Llama 3 8B base model -- on the openassistant-guanaco dataset, without using tricks like quantization or LoRA. I'm doing this as a way to try to understand how to do full-on multi-GPU training of a model that cannot be trained on just one GPU.
I've been building up to this goal gradually; so far, I've:
- Fine-tuned a 0.5B model on my own machine.
- Done the same, but in the cloud using Lambda Labs.
- Run some multi-GPU training, but using the GPUs to run larger batches for the 0.5B model -- which in turn means training faster -- rather than to train a larger model.
- Successfully fine-tuned the 8B model across multiple GPUs using ZeRO and DeepSpeed, but with the optimizer offloaded to CPU.
- Done some initial experiments into memory usage to find out why I had to offload the optimizer, using the 0.5B model locally.
The experiments I did last time around were to find out why, when the
DeepSpeed estimate_zero3_model_states_mem_needs_all_live function said that
I would need just less than 18 GiB of VRAM per GPU to train the 8B model without
offloading anything, in reality I needed 40 GiB and still had to offload the
optimizer.
At the end of the experiments, I'd found:
- At least part of the problem with the estimation function was that it did not take account of the sequence length being used for the training. In my very first post about fine-tuning, I'd found that the longer the sequence length, the more VRAM needed to tune (which makes perfect sense). My guess is that this is because the function is not designed for LLMs, but is rather for fixed-input models where the memory usage is more stable.
- The memory usage for PyTorch is classified two ways: the "allocated" memory, which is actually in use for tensors, and the "reserved" memory, which is the allocated memory plus -- at least, from my reading of the docs at the time -- whatever is used for caches.
- With a very short sequence length -- I had tested with it set to 10 -- the allocated memory in the train was closer to the results from the estimation function: in the case of the 0.5B model I was testing with locally, the function returned 8 GiB and the allocated VRAM was about 10 GiB.
- Some extra memory above the allocated amount was needed for training; my take on that was that caches were (understandably) important.
- However, it was possible to reduce the amount of reserved memory beyond the allocated (and to tell PyTorch to keep going even if it didn't have as much cache space as it wanted) if you set an environment variable:
export PYTORCH_CUDA_ALLOC_CONF=expandable_segments:True
This time around I wanted to take a more systematic look at the effects of the sequence length and of that environment variable on memory usage and training speed. I'd previously been assuming that VRAM usage would vary linearly with sequence length, but I had no evidence for that. And while it looked like training speed decreased with increasing sequence length, I didn't have any hard numbers. Time to fix that hole in my knowledge!
The first step: do some careful measurements of those numbers on the 0.5B model locally. That's what this post is about -- the next one will be for the 8B model running on Lambda Labs.
Messing around with fine-tuning LLMs, part 5 -- exploring memory usage
My goal is to fine-tune an 8B model -- specifically, the Llama 3 8B base model -- on the openassistant-guanaco dataset, without using tricks like quantization or LoRA. I'm doing this as a way to try to understand how to do full-on multi-GPU training of a model that cannot be trained on just one GPU.
I've been building up to this goal gradually; so far, I've:
- Fine-tuned a 0.5B model on my own machine.
- Done the same, but in the cloud using Lambda Labs.
- Run some multi-GPU training, but using the GPUs to run larger batches for the 0.5B model -- which in turn means training faster -- rather than to train a larger model.
- Successfully fine-tuned the 8B model across multiple GPUs using ZeRO and DeepSpeed, but with the optimizer offloaded to CPU.
This time around, I wanted to find out why I had to offload the optimizer, because it didn't seem like it should be necessary. Hugging Face helpfully document a DeepSpeed function that you can call to estimate the VRAM requirements for training a model with ZeRO, and when I ran it against the 8B model, I got this:
(fine-tune) ubuntu@130-61-28-84:~/fine-tune-2024-04$ python -c 'from transformers import AutoModel; \
from deepspeed.runtime.zero.stage3 import estimate_zero3_model_states_mem_needs_all_live; \
model = AutoModel.from_pretrained("meta-llama/Meta-Llama-3-8B"); \
estimate_zero3_model_states_mem_needs_all_live(model, num_gpus_per_node=8, num_nodes=1)'
[2024-05-17 23:19:31,667] [INFO] [real_accelerator.py:203:get_accelerator] Setting ds_accelerator to cuda (auto detect)
[WARNING] async_io requires the dev libaio .so object and headers but these were not found.
[WARNING] async_io: please install the libaio-dev package with apt
[WARNING] If libaio is already installed (perhaps from source), try setting the CFLAGS and LDFLAGS environment variables to where it can be found.
[WARNING] Please specify the CUTLASS repo directory as environment variable $CUTLASS_PATH
[WARNING] sparse_attn requires a torch version >= 1.5 and < 2.0 but detected 2.2
[WARNING] using untested triton version (2.2.0), only 1.0.0 is known to be compatible
Loading checkpoint shards: 100%|============================================================================================================| 4/4 [00:02<00:00, 1.61it/s]
Estimated memory needed for params, optim states and gradients for a:
HW: Setup with 1 node, 8 GPUs per node.
SW: Model with 7504M total params, 525M largest layer params.
per CPU | per GPU | Options
188.72GB | 1.96GB | offload_param=cpu , offload_optimizer=cpu , zero_init=1
335.50GB | 1.96GB | offload_param=cpu , offload_optimizer=cpu , zero_init=0
167.75GB | 3.70GB | offload_param=none, offload_optimizer=cpu , zero_init=1
335.50GB | 3.70GB | offload_param=none, offload_optimizer=cpu , zero_init=0
23.48GB | 17.68GB | offload_param=none, offload_optimizer=none, zero_init=1
335.50GB | 17.68GB | offload_param=none, offload_optimizer=none, zero_init=0
It was saying that I only needed 17.68 GiB VRAM per GPU with no optimizer offload -- but I had needed to offload it even though I had 40 GiB per GPU. Why was that? What was I doing wrong? The documents that mention that function also say:
these are just the memory requirements for the parameters, optimizer states and gradients, and you'll need a bit more for the CUDA kernels and activations
...but 22 GiB extra is more than "a bit more". I must have been misunderstanding something.
Digging into this took an embarrassing amount of time -- I started work on it shortly after publishing my last post in this series, so that's been more than a month! And it's embarrassing that I took so long because the reason why I should not trust the number reported by that script was staring me in the face from the start, and involved something I'd discovered in my first explorations into this stuff.
Still, I learned a lot over the course of these investigations, so I think it's worth showing at least some of the journey. The post below is a distilled version of my lab notes and is a little rambling, but you might find it interesting if you're also digging into memory usage during LLM training as a beginner. If not, and you're looking for more carefully planned experiments and results, hopefully the next post in this series will have more of those :-)
Let's get going.
Messing around with fine-tuning LLMs, part 4 -- training cross-GPU.
My goal is to fine-tune an 8B model -- specifically, the Llama 3 8B base model -- on the openassistant-guanaco dataset. I'm doing this as a way to try to understand how to do full-on multi-GPU training of a model that literally cannot be trained on just one GPU. I've been building up to this goal gradually; so far, I've:
- Fine-tuned a 0.5B model on my own machine.
- Done the same, but in the cloud using Lambda Labs.
- Run some multi-GPU training, but using the GPUs to run larger batches -- which in turn means training faster -- rather than to train a larger model.
In that last step, I'd found a very useful page in the Hugging Face documentation. It split multi-GPU situations into three categories:
- Your model fits onto on a GPU.
- Your model doesn't fit onto a GPU (but the layers taken individually do).
- The largest layer in your model is so big that it doesn't fit onto a GPU.
I'd interpreted that first point as "you can load the model onto just one GPU" -- that is, you can run inference on it because all of the parameters fit there (with some overhead for the data, activations, etc). However, my experiences showed that it meant "you can train the model on one GPU", which takes up significantly more VRAM than inference does. The suggested approaches they had for that category were all about having the model loaded and training on each GPU, which is good for speeding up training by training on multiple batches simultaneously, but doesn't help if you want multiple GPUs simply because you can't train the model on one GPU alone.
So my goal this time was to change my training strategy to use a technique that allowed the training of the entire model to be split across GPUs. Here's what I did.
Messing around with fine-tuning LLMs, part 3 -- moar GPUs
Having fine-tuned a 0.5B model on my own machine, I wanted to try the same kind of tuning, but with an 8B model. I would need to do that on a cloud provider, because my own machine with its RTX 3090 would definitely not be up to the job, and I'd tried out Lambda Labs and found that it worked pretty well.
Importantly, I was going to need to train with multiple GPUs in order to do this. The Lambda Labs options open to me last time around were:
- 1x H100 (80GiB PCIe) at $2.49/hour
- 1x A10 (24GiB PCIe) at $0.75/hour
- 1x A100 (40GiB SXM4) at $1.29/hour
- 8x A100 (40GiB SXM4) at $10.32/hour
The last of those looked like it should be ample for my needs, which I'd estimated at being 160GiB VRAM (vs 320GiB on that monster machine). But before trying to use a multi-GPU setup to fine-tune a model I'd never worked with before, I figured it would be a good idea to try with the model that I've been using to date. The plan was:
- Spin up a 1x A100 and run the same fine-tune as I've been doing on it.
- If all was well, try again with the 8x A100 instance and start to learn about multi-GPU training.
Then once that was all done, I'd hopefully be in a good position to try the fine-tune for the bigger model.
Here's how it went.
Messing around with fine-tuning LLMs, part 2 -- to the cloud!
Having fine-tuned a 0.5B model on my own machine, I wanted to try the same kind of tuning, but with an 8B model. My experiments suggested to me that the VRAM required for the tuning was roughly linear with two meta-parameters -- the length of the samples and the batch size -- and I'd found resources online that suggested that it was also linear with the number of parameters.
The 16x scale going from 0.5B parameters to 8B would suggest that I would need 16x24GiB to run this fine-tune, which would be 384GiB. However, the chart I'd seen before suggested I could do it with a bit more than 160GiB -- that being the number they gave for a 7B parameter model.
What I clearly needed to do was find a decent-looking cloud GPU platform where I could start with a smaller machine and easily switch over to a larger one if it wasn't sufficient. Here are my first steps, running one of my existing fine-tune notebooks on a cloud provider.
Messing around with fine-tuning LLMs
Fine-tuning an LLM is how you take a base model and turn it into something that can actually do something useful. Base models are LLMs that have been trained to learn to predict the next word on vast amounts of text, and they're really interesting to play with, but you can't really have a conversation with one. When you ask them to complete some text, they don't know whether you want to complete it as part of a novel, a technical article, or an unhinged tweetstorm. (The obvious joke about which type of people the same applies to is left as an exercise for the reader.)
Chat-like AIs like ChatGPT become possible when a base model has been fine-tuned on lots of texts representing transcriptions (real or fake) of conversations, so that they specialise in looking at texts like this:
Human: Hello!
Bot: Hello, I'm a helpful bot. What can I do for you today?
Human: What's the capital city of France?
Bot:
...and can work out that the next word should be something like "The", and then "capital", and so on to complete the sentence: "of France is Paris. Is there anything else I can help you with?"
Getting a solid intuition for how this all works felt like an interesting thing to do, and here are my lab notes on the first steps.
LLM Quantisation Weirdness
I bought myself an Nvidia RTX 3090 for Christmas to play around with local AI models. Serious work needs larger, more powerful cards, and it's easy (and not that expensive) to rent such cards by the minute from the likes of Paperspace. But the way I see it, I'm not going to be doing any serious work -- and what I really want to do is be able to run little experiments quickly and easily without worrying about spinning up a machine, getting stuff onto it, and so on.
One experiment that I tried the other day was to try to get a mental model of how model size and quantisation affect the quality of responses from LLMs. Quantisation is the process of running a model that has, say, 16 bits for each of its parameters with the parameters clipped to eight bits, four bits, or even less -- people have found that it often has a surprisingly small effect on output quality, and I wanted to play with that. Nothing serious or in-depth -- just trying stuff out with different model sizes and quantisations, and running a few prompts through them to see how the outputs differed.
I was comparing three sizes of the Code Llama HF model, with different quantisations:
- codellama/CodeLlama-7b-Instruct-hf, which has 7b parameters, in "full-fat", 8-bit and 4-bit
- codellama/CodeLlama-13b-Instruct-hf, which has 13b parameters, in 8-bit and 4-bit
- codellama/CodeLlama-34b-Instruct-hf, which has 34b parameters, in 4-bit
Code Llama is a model from Meta, and the HF version ("Human Feedback") is designed to receive questions about programming (with specific formatting), and to reply with code. I chose those particular quantisations because the 13b model wouldn't fit in the 3090's 24GiB RAM without quantisation to a least 8-bit, and the 34b model would only fit if it was 4-bit quantised.
The quality of the response to my test question was not too bad with any of these, apart from codellama/CodeLlama-34b-Instruct-hf in 4-bit, which was often (but not always) heavily glitched with missing tokens -- that is, it was worse than codellama/CodeLlama-7b-Instruct-hf in 4-bit. That surprised me!
I was expecting quantisation to worsen the results, but not to make a larger model worse than a smaller one at the same level of quantisation. I've put a repo up on GitHub to see if anyone can repro these results, and to find out if anyone has any idea why it's happening.